Try out KubeBlocks with Playground
Installation
Prerequisite for Local Env
Upgrade KubeBlocks
Connect Database
Maintenance
Backup and Restore
In Place Update
Resource Scheduling
Cross K8s Deployment
Instance Template
Observability
User Management
Handle an Exception
Developer
Add an add-on to KubeBlocks
External Component
So far, you've learned the definition, backup, and configuration of single-component clusters (e.g., Oracle-MySQL).
This tutorial takes NebulaGraph as an example to demonstrate how to integrate a multi-component cluster and address several common issues in multi-component configurations. You can find more details in this repository.
First, take a look at the overall architecture of NebulaGraph.
NebulaGraph applies the separation of storage and computing architecture and consists of three services: the Graph Service, the Meta Service, and the Storage Service. The following figure shows the architecture of a typical NebulaGraph cluster.
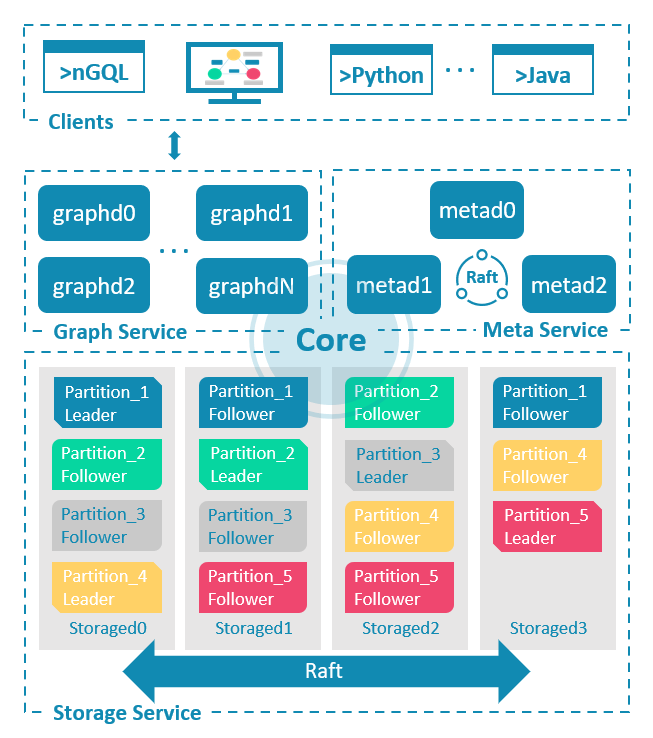
If the client is considered, the fourth component is:
Now you've learned the four components of NebulaGraph, and how each component is started and configured.
Similar to a single-component cluster, you can quickly assemble the definition for a multi-component cluster.
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ClusterDefinition
metadata:
name: nebula
spec:
componentDefs:
- name: nebula-console # client
workloadType: Stateless
characterType: nebula
podSpec: ...
- name: nebula-graphd # graphd
workloadType: Stateful
podSpec: ...
- name: nebula-metad # metad
workloadType: Stateful
podSpec: ...
- name: nebula-storaged # storaged
workloadType: Stateful
podSpec: ...
---
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ClusterVersion
metadata:
name: nebula-3.5.0
spec:
clusterDefinitionRef: nebula # clusterdef name
componentVersions:
- componentDefRef: nebula-console # Specify image for client
versionsContext:
containers:
- name: nebula-console
image: ...
- componentDefRef: nebula-graphd # Specify image for graphd
versionsContext:
containers:
- name: nebula-graphd
image:
- componentDefRef: nebula-metad # Specify image for metad
versionsContext:
containers:
- name: nebula-metad
image: ...
- componentDefRef: nebula-storaged # Specify image for storaged
versionsContext:
containers:
- name: nebula-storaged
image: ...
The above YAML file provides an outline of the ClusterDefinition and ClusterVersion for NebulaGraph. Corresponding to the first figure, four components (including the client) and their version information are specified.
If each component can be started independently, the information provided in the above YAML file would be sufficient.
However, it can be observed that in a multi-component cluster, there are often inter-component references. So, how to specify the references thereof?
As discovered, components may refer to each other and the figure below shows the inter-component references in a NebulaGraph cluster. For example,
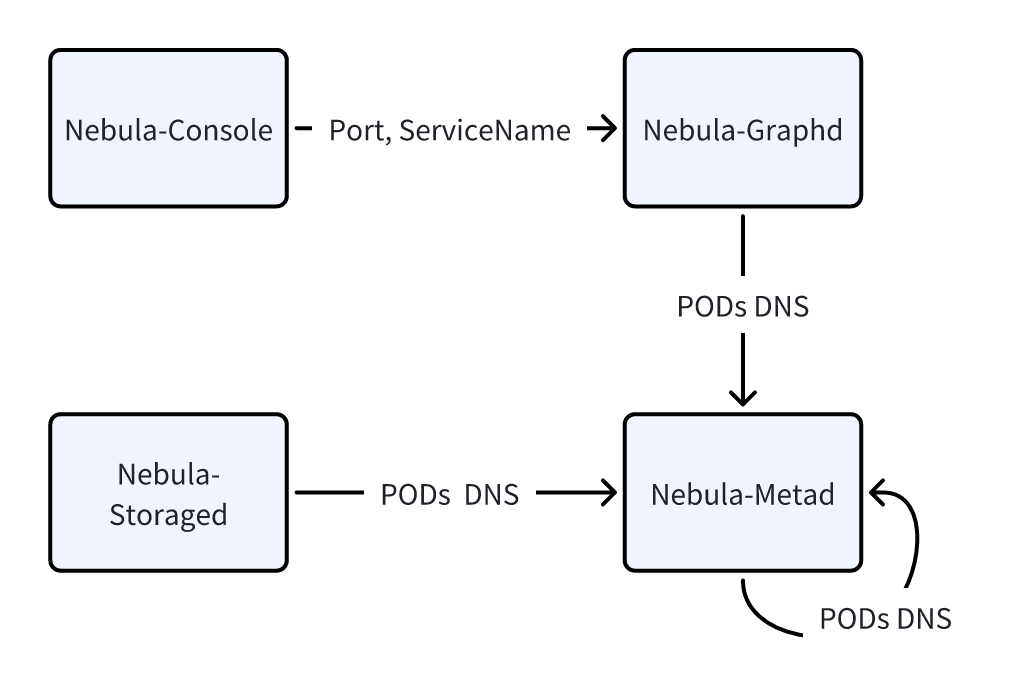
Therefore, three common types of inter-component references are:
Service Reference
E.g., Nebula-Console needs to obtain the service name of Nebula-Graphd.
HostName Reference
E.g., Nebula-Graphd needs to configure the DNS of all Pods of Nebula-metad. This reference typically points to a stateful component.
Field Reference
E.g., Nebula-Console needs to obtain a service port name of Nebula-Graphd.
To ensure that the cluster starts normally, the above information needs to be injected into the Pod through environment variables (whether it is loaded through configmap or defined as pod env).
In KubeBlocks, the ComponentDefRef API can be used to achieve the goal. It introduces the following APIs:
componentDefName, used to specify the name of the component definition that is being referenced to.componentRefEnv, which defines a set of environment variables that need to be injected.
name defines the name of the injected environment variable.valueFrom defines the source of the variable value.Next, you will learn how ComponentDefRef deals with the three types of references mentioned above.
Case 1: Nebula-Console needs to obtain the service name of Nebula-Graphd.
When defining nebula-console, add the following definitions (as componentDefRef shows):
- name: nebula-console
workloadType: Stateless
characterType: nebula
componentDefRef:
- componentDefName: nebula-graphd
componentRefEnv:
- name: GRAPHD_SVC_NAME
valueFrom:
type: ServiceRef
nebula-graphd.GRAPHD_SVC_NAME.ServerRef, indicating that the value comes from the service name of the referenced component.In KubeBlocks, if you've defined the service for a component, when you create a cluster, KubeBlocks will create a service named {clusterName}-{componentName} for that component.
Case 2: Nebula-Graphd needs to configure the DNS of all PODs of Nebula-Metad.
- name: nebula-graphd
workloadType: Statelful
componentDefRef:
- componentDefName: nebula-metad
componentRefEnv:
- name: NEBULA_METAD_SVC
valueFrom:
type: HeadlessServiceRef
format: $(POD_FQDN):9559 # Optional, specify value format
nebula-metad.NEBULA_METAD_SVC.HeadlessServiceRef.
KubeBlocks provides three built-in variables as placeholders and they will be replaced with specific values when the cluster is created:
${POD_ORDINAL}, which is the ordinal number of the Pod.${POD_NAME}, which is the name of the Pod, formatted as {clusterName}-{componentName}-{podOrdinal}.${POD_FQDN}, which is the Fully Qualified Domain Name (FQDN) of the Pod.In KubeBlocks, each stateful component has a Headless Service named headlessServiceName = {clusterName}-{componentName}-headless by default.
Therefore, the format of the Pod FQDN of each stateful component is:
POD_FQDN = {clusterName}-{componentName}-{podIndex}.{headlessServiceName}.{namespace}.svc.
Case 3: Nebula-Console needs to obtain a service port name of Nebula-Graphd.
When defining nebula-console, add the following configurations (as componentDefRef shows):
- name: nebula-console
workloadType: Stateless
characterType: nebula
componentDefRef:
- componentDefName: nebula-graphd
componentRefEnv:
- name: GRAPHD_SVC_PORT
valueFrom:
type: FieldRef
fieldPath: $.componentDef.service.ports[?(@.name == "thrift")].port
nebula-graphd.GRAPHD_SVC_PORT.FieldRef, indicating that the value comes from a certain property value of the referenced component and is specified by fieldPath.fieldPath provides a way to parse property values through JSONPath syntax.
When parsing JSONPath, KubeBlocks registers two root objects by default:
Therefore, in fieldPath, you can use $.componentDef.service.ports[?(@.name == "thrift")].port to obtain the port number named thrift in the service defined by this component.
This tutorial takes NebulaGraph as an example and introduces several types and solutions of inter-component references.
In addition to NebulaGraph, engines like GreptimeDB, Pulsar, RisingWave and StarRocks also adopt componentDefRef API to deal with component references. You can also refer to their solutions.
Since Nebula-Graphd, Nebula-Metad and Nebula-Storaged all require the FQDN of each Pod in Nebula-Metad, you don't need to configure them repeatedly.
Quickly configure them with YAML anchors.
- name: nebula-graphd
# ...
componentDefRef:
- &metadRef # Define an anchor with `&`
componentDefName: nebula-metad
componentRefEnv:
- name: NEBULA_METAD_SVC
valueFrom:
type: HeadlessServiceRef
format: $(POD_FQDN){{ .Values.clusterDomain }}:9559
joinWith: ","
- name: nebula-storaged
componentDefRef:
- *metadRef # Use the anchor with `*` to avoid duplication