Getting Started
Concepts and Features
Backup and Restore
In Place Update
Instance Template
Trouble Shooting
Upgrade & Migration
References
KubeBlocks is an open-source Kubernetes operator for databases (more specifically, for stateful applications, including databases and middleware like message queues), enabling users to run and manage multiple types of databases on Kubernetes. As far as we know, most database operators typically manage only one specific type of database. For example:
In contrast, KubeBlocks is designed to be a general-purpose database operator. This means that when designing the KubeBlocks API, we didn’t tie it to any specific database. Instead, we abstracted the common features of various databases, resulting in a universal, engine-agnostic API. Consequently, the operator implementation developed around this abstract API is also agnostic to the specific database engine.
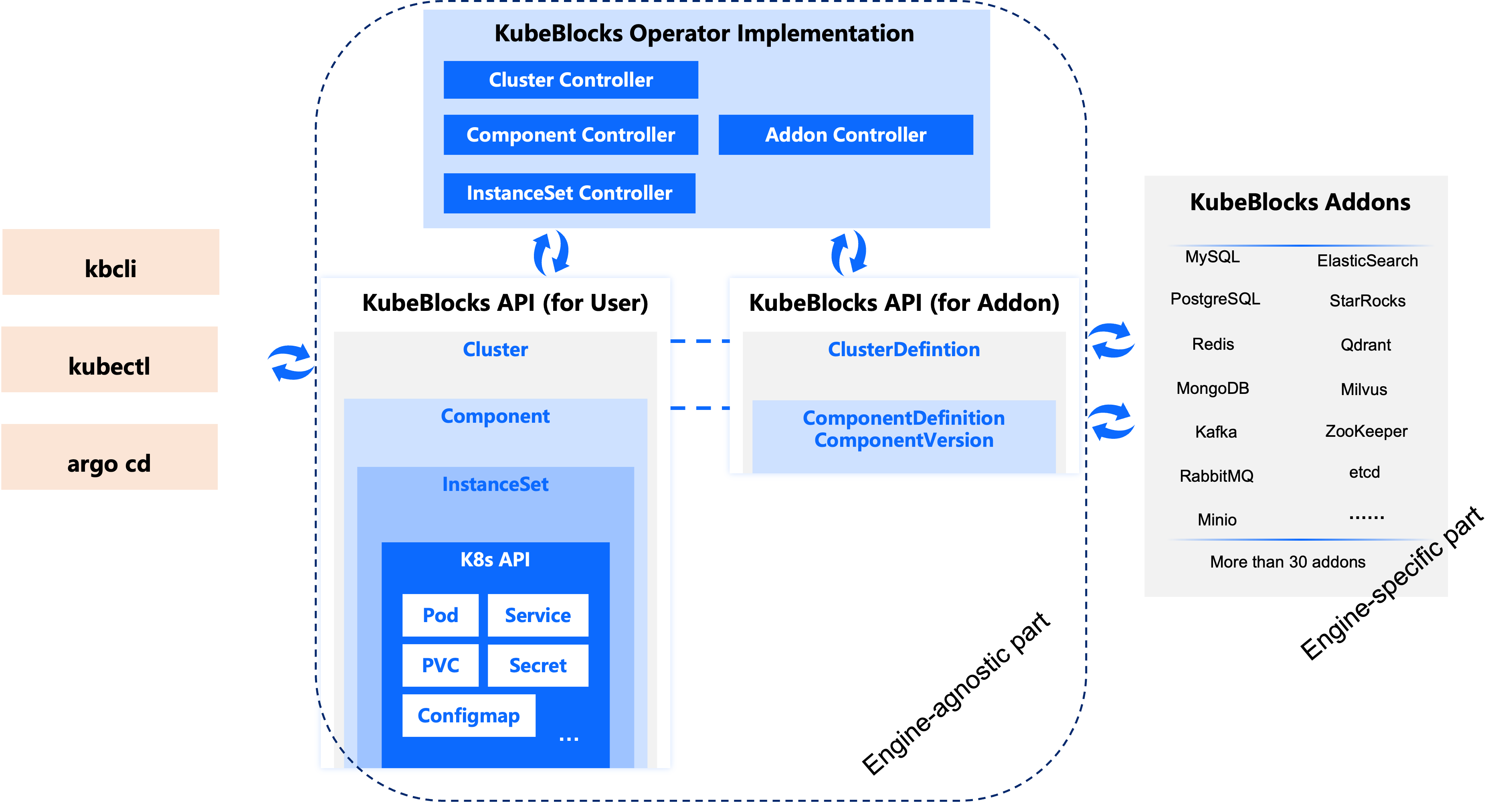
In above diagram, Cluster, Component, and InstanceSet are all CRDs provided by KubeBlocks. If you'd like to learn more about them, please refer to concepts.
KubeBlocks offers an Addon API to support the integration of various databases. For instance, we currently have the following KubeBlocks Addons for mainstream open-source database engines:
For a detailed list of Addons and their features, please refer to supported addons.
The unified API makes KubeBlocks an excellent choice if you need to run multiple types of databases on Kubernetes. It can significantly reduce the learning curve associated with mastering multiple operators.
Here is an example of how to use KubeBlocks' Cluster API to write a YAML file and create a MySQL Cluster with two replicas.
apiVersion: apps.kubeblocks.io/v1
kind: Cluster
metadata:
name: test-mysql
namespace: demo
spec:
terminationPolicy: Delete
componentSpecs:
- name: mysql
componentDef: "mysql-8.0"
serviceVersion: 8.0.35
disableExporter: false
replicas: 2
resources:
limits:
cpu: '0.5'
memory: 0.5Gi
requests:
cpu: '0.5'
memory: 0.5Gi
volumeClaimTemplates:
- name: data
spec:
storageClassName: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
Then, here comes the magic: with just a few modifications to some fields, you can create a PostgreSQL Cluster with two replicas! The same applies to MongoDB and Redis (the Redis example is slightly longer because it creates two components: redis-server and sentinel), and this approach works with a long list of engines.
apiVersion: apps.kubeblocks.io/v1
kind: Cluster
metadata:
name: test-pg
namespace: demo
spec:
terminationPolicy: Delete
clusterDef: postgresql
topology: replication
componentSpecs:
- name: postgresql
serviceVersion: 16.4.0
disableExporter: true
replicas: 2
resources:
limits:
cpu: "0.5"
memory: "0.5Gi"
requests:
cpu: "0.5"
memory: "0.5Gi"
volumeClaimTemplates:
- name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
apiVersion: apps.kubeblocks.io/v1
kind: Cluster
metadata:
name: test-mongo
namespace: demo
spec:
terminationPolicy: Delete
clusterDef: mongodb
topology: replicaset
componentSpecs:
- name: mongodb
serviceVersion: "6.0.27"
replicas: 3
resources:
limits:
cpu: '0.5'
memory: 0.5Gi
requests:
cpu: '0.5'
memory: 0.5Gi
volumeClaimTemplates:
- name: data
spec:
storageClassName: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
apiVersion: apps.kubeblocks.io/v1alpha1
kind: Cluster
metadata:
name: test-redis
namespace: demo
spec:
terminationPolicy: Delete
componentSpecs:
- name: redis
componentDef: redis-7
replicas: 2
resources:
limits:
cpu: '0.5'
memory: 0.5Gi
requests:
cpu: '0.5'
memory: 0.5Gi
volumeClaimTemplates:
- name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
- name: redis-sentinel
componentDef: redis-sentinel
replicas: 3
resources:
limits:
cpu: '0.5'
memory: 0.5Gi
requests:
cpu: '0.5'
memory: 0.5Gi
volumeClaimTemplates:
- name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
This means that managing multiple databases on Kubernetes becomes simple, efficient, and standardized, saving you a lot of time that would otherwise be spent searching through manuals and API references.
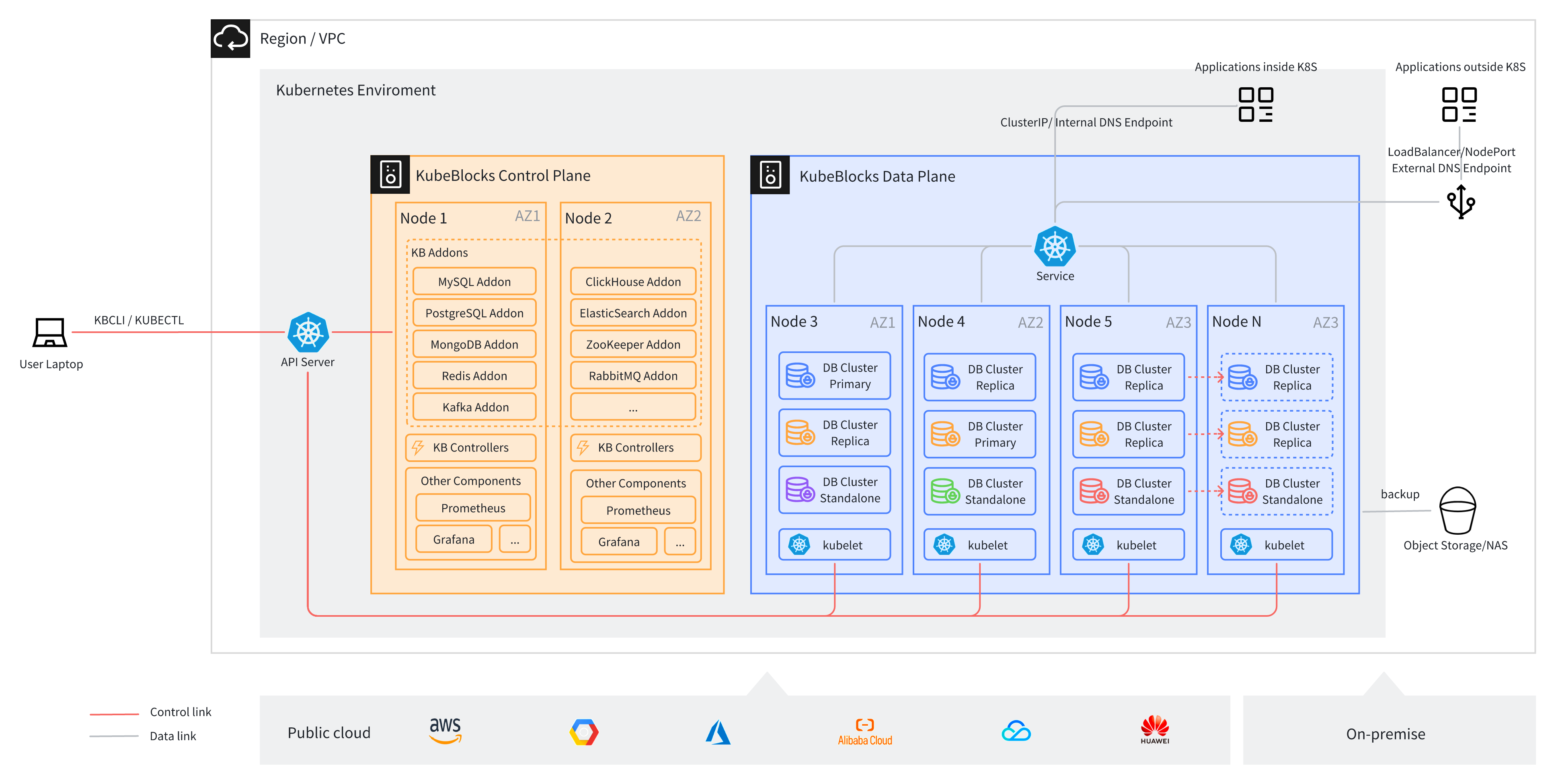
kbcli, which makes operating KubeBlocks CRs on Kubernetes more straightforward and reduces keystrokes. For those well-versed in Kubernetes, kbcli can be used alongside kubectl to provide a more streamlined way of performing operations.Below is a typical diagram illustrating the deployment of KubeBlocks in a cloud environment.
Kubernetes should be deployed in an environment where nodes can communicate with each other over the network (e.g., within a VPC). The KubeBlocks Operator is deployed in a dedicated namespace (kb-system), while database instances are deployed in user-specified namespaces.
In a production environment, we recommend deploying the KubeBlocks Operator (along with Prometheus and Grafana, if installed) on different nodes from the databases. By default, multiple replicas of a database cluster are scheduled to run on different nodes using anti-affinity rules to ensure high availability. Users can also configure AZ-level anti-affinity to distribute database replicas across different availability zones (AZs), thereby enhancing disaster recovery capabilities.
Each database replica runs within its own Pod. In addition to the container running the database process, the Pod includes several sidecar containers: one called lorry (which will be renamed to kbagent starting from KubeBlocks v1.0) that executes Action commands from the KubeBlocks controller, and another called config-manager that manages database configuration files and supports hot updates. Optionally, The engine's Addon may have an exporter container to collect metrics for Prometheus monitoring.