Failure simulation and automatic recovery
As an open-source data management platform, Kubeblocks currently supports over thirty database engines and is continuously expanding. Due to the varying high availability capabilities of databases, KubeBlocks has designed and implemented a high availability (HA) system for database instances. The KubeBlocks HA system uses a unified HA framework to provide high availability for databases, allowing different databases on KubeBlocks to achieve similar high availability capabilities and experiences.
This tutorial uses MySQL Community edition as an example to demonstrate its fault simulation and recovery capabilities.
Recovery simulation
The faults here are all simulated by deleting a pod. When there are sufficient resources, the fault can also be simulated by machine downtime or container deletion, and its automatic recovery is the same as described here.
Before you start
-
Create a MySQL Replication Cluster, refer to Create a MySQL cluster.
-
Run
kubectl get cd mysql -o yamlto check whether rolechangedprobe is enabled in the MySQL Replication (it is enabled by default). If the following configuration exists, it indicates that it is enabled:probes:
roleProbe:
failureThreshold: 2
periodSeconds: 1
timeoutSeconds: 1
Primary pod fault
Steps:
- kubectl
- kbcli
-
View the pod role of the MySQL Replication Cluster. In this example, the primary pod's name is
mycluster-mysql-0.kubectl get pods --show-labels -n demo | grep role
-
Delete the primary pod
mycluster-mysql-0to simulate a pod fault.kubectl delete pod mycluster-mysql-0 -n demo
-
Check the status of the pods and Replication Cluster connection.
The following example shows that the roles of pods have changed after the old primary pod was deleted and
mycluster-mysql-1is elected as the new primary pod.kubectl get pods --show-labels -n demo | grep role
-
View the MySQL Replication Cluster information. View the primary pod name in
Topology. In this example, the primary pod's name ismycluster-mysql-0.kbcli cluster describe mycluster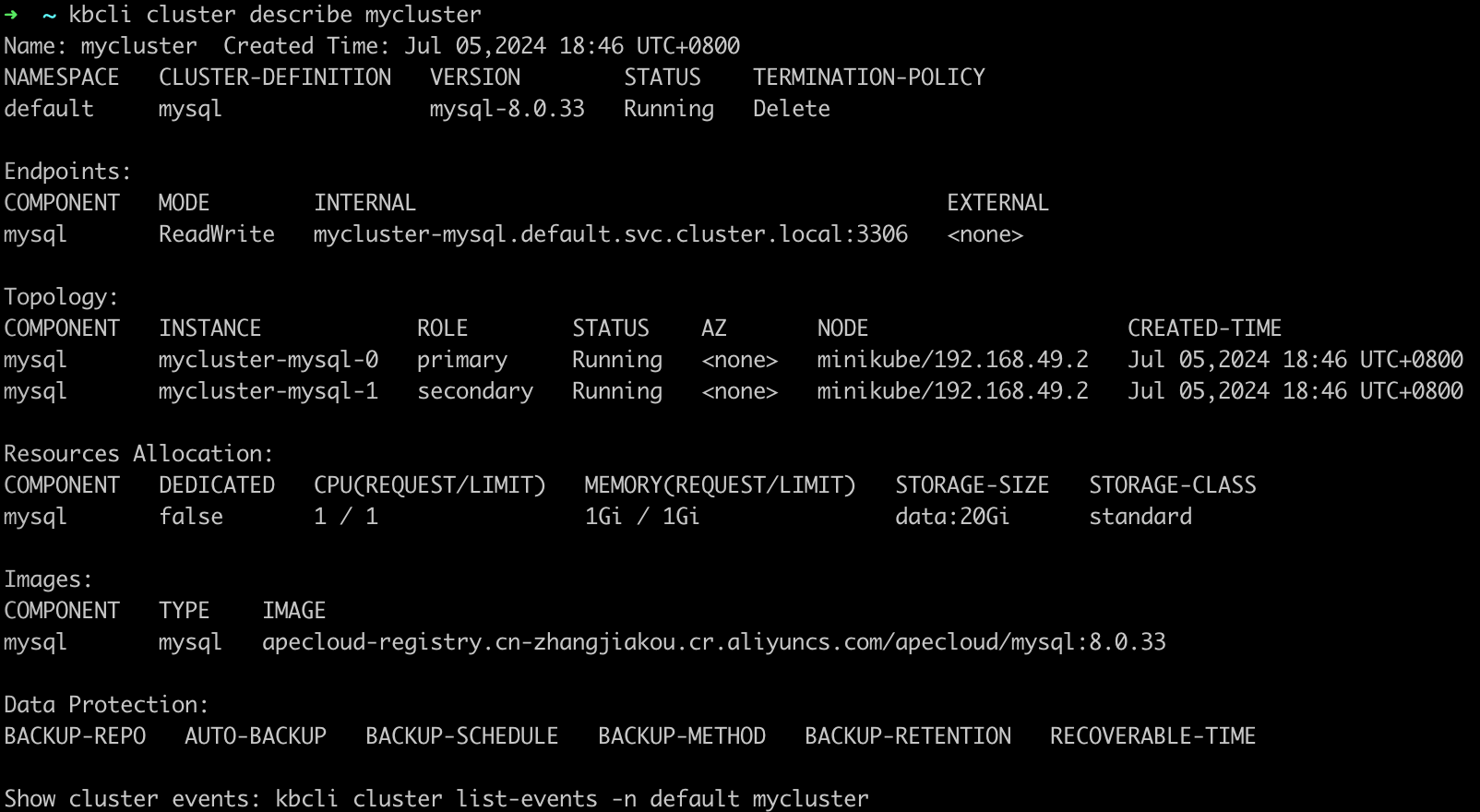
-
Delete the primary pod
mycluster-mysql-0to simulate a pod fault.kubectl delete pod mycluster-mysql-0
-
Run
kbcli cluster describeto check the status of the pods and Replication Cluster connection.Results
The following example shows that the roles of pods have changed after the old primary pod was deleted and
mycluster-mysql-1is elected as the new primary pod.kbcli cluster describe mycluster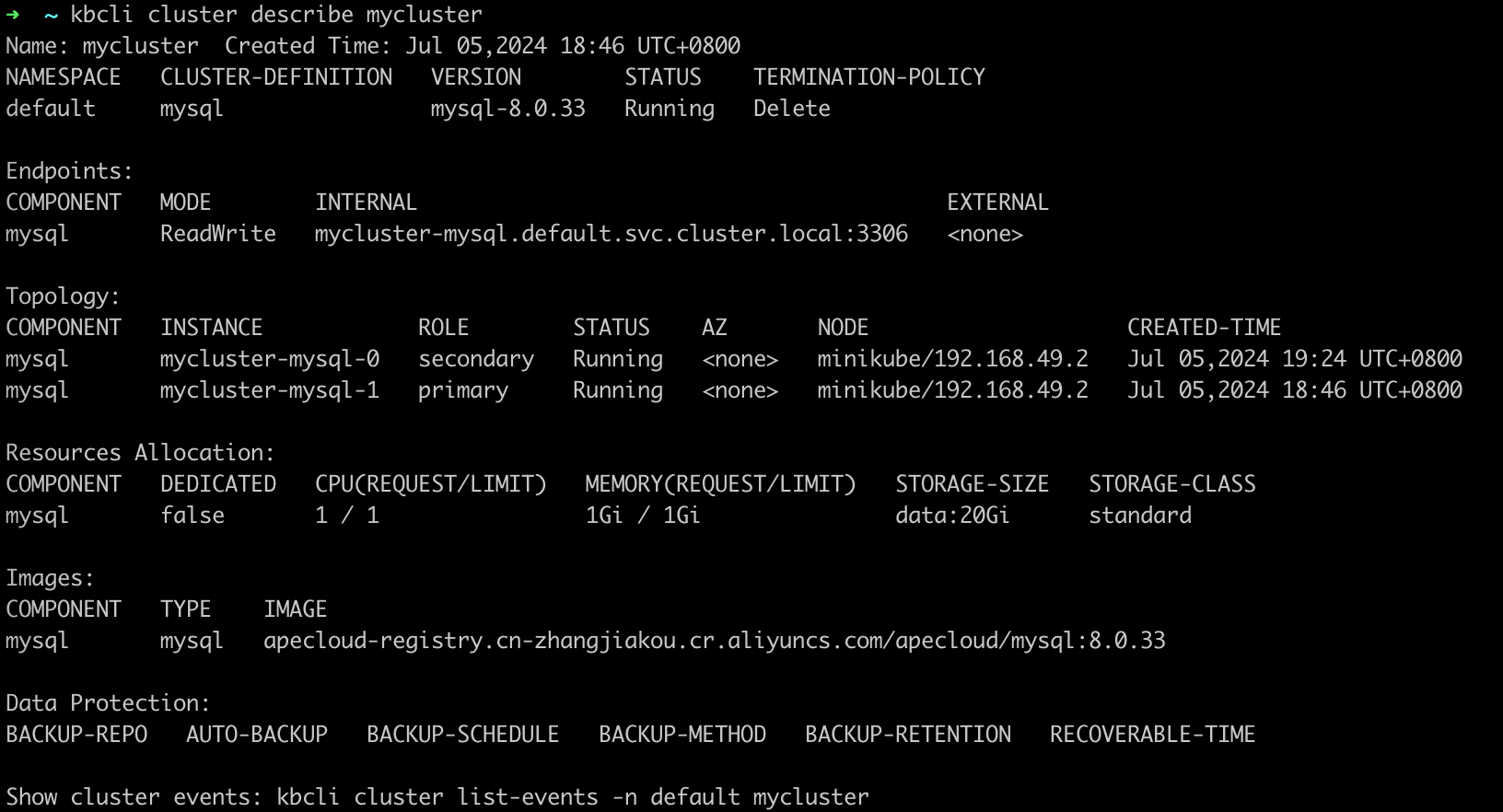
It shows that this MySQL Replication Cluster can be connected within seconds.
How the automatic recovery works
After the primary pod is deleted, the MySQL Replication Cluster elects a new primary pod. In this example, mycluster-mysql-1 is elected as the new primary pod. KubeBlocks detects that the primary pod has changed, and sends a notification to update the access link. The original exception node automatically rebuilds and recovers to the normal Replication Cluster state. It normally takes 30 seconds from exception to recovery.
Secondary pod exception
Steps:
- kubectl
- kbcli
-
View the pod role again and in this example, the secondary pod is
mycluster-mysql-0.kubectl get pods --show-labels -n demo | grep role
-
Delete the secondary pod
mycluster-mysql-0.kubectl delete pod mycluster-mysql-0 -n demo
-
Open another terminal page and view the pod status. You can find the secondary pod
mycluster-mysql-0isTerminating.kubectl get pod -n demo
View the pod roles again.

-
View the MySQL Replication Cluster information and view the secondary pod name in
Topology. In this example, the secondary pod ismycluster-mysql-0.kbcli cluster describe mycluster -
Delete the secondary pod mycluster-mysql-0.
kubectl delete pod mycluster-mysql-0
-
View the Replication Cluster status and you can find the secondary pod is being terminated in
Component.Instance.kbcli cluster describe mycluster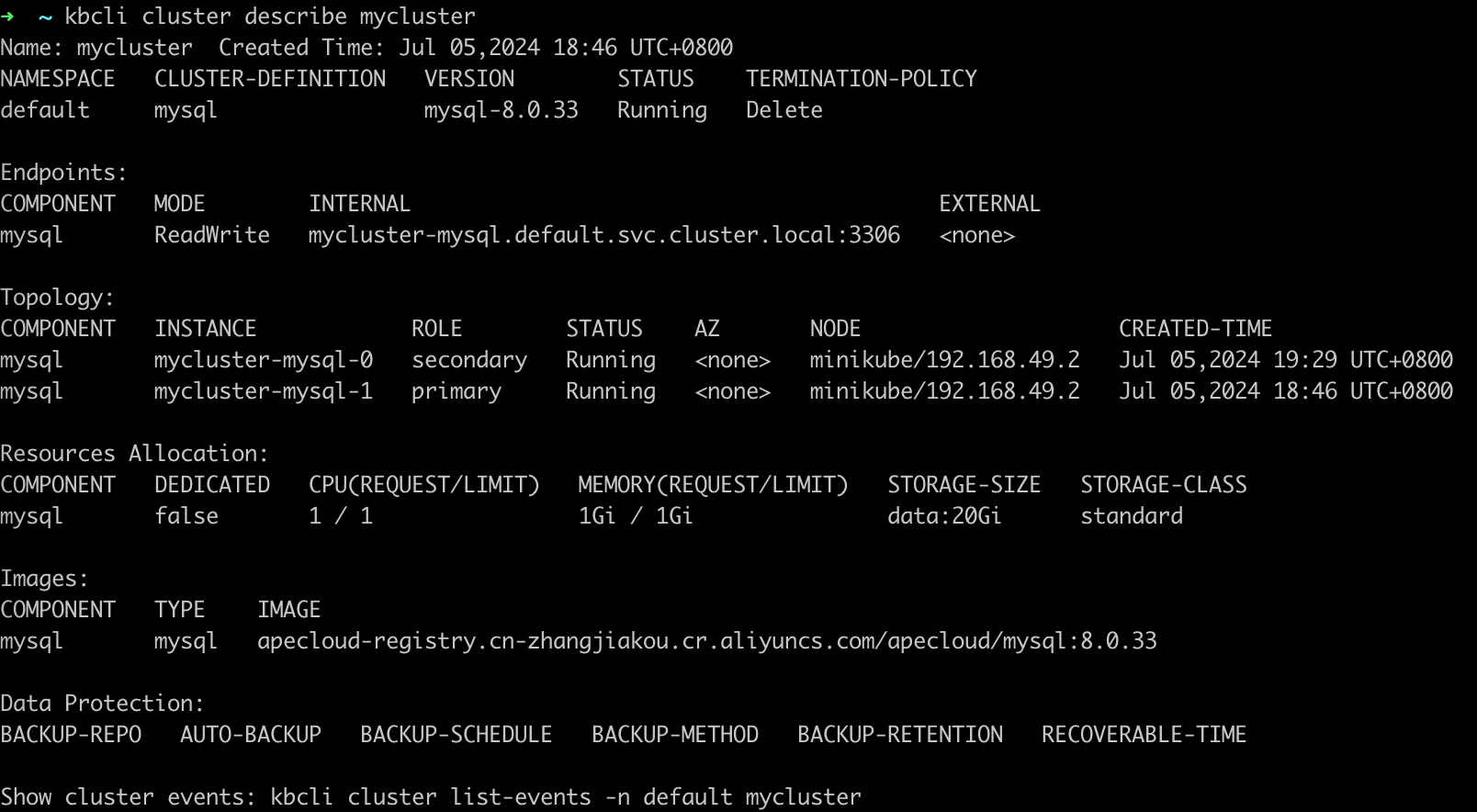
How the automatic recovery works
One secondary pod exception doesn't trigger re-electing of the primary pod or access link switch, so the R/W of the cluster is not affected. The secondary pod exception triggers recreation and recovery. The process takes no more than 30 seconds.
Both pods exception
Steps:
- kubectl
- kbcli
-
View the role of pods.
kubectl get pods --show-labels -n demo | grep role
-
Delete both pods.
kubectl delete pod mycluster-mysql-0 mycluster-mysql-1 -n demo
-
Open another terminal page and view the pod status. You can find the pods are terminating.
kubectl get pod -n demo
-
View the pod roles and you can find a new primary pod is elected.
kubectl get pods --show-labels -n demo | grep role
-
Run the command below to view the MySQL Replication Cluster information and view the pods' names in
Topology.kbcli cluster describe mycluster -
Delete all pods.
kubectl delete pod mycluster-mysql-1 mycluster-mysql-0
-
Run the command below to view the deleting process. You can find the pods are pending.
kbcli cluster describe mycluster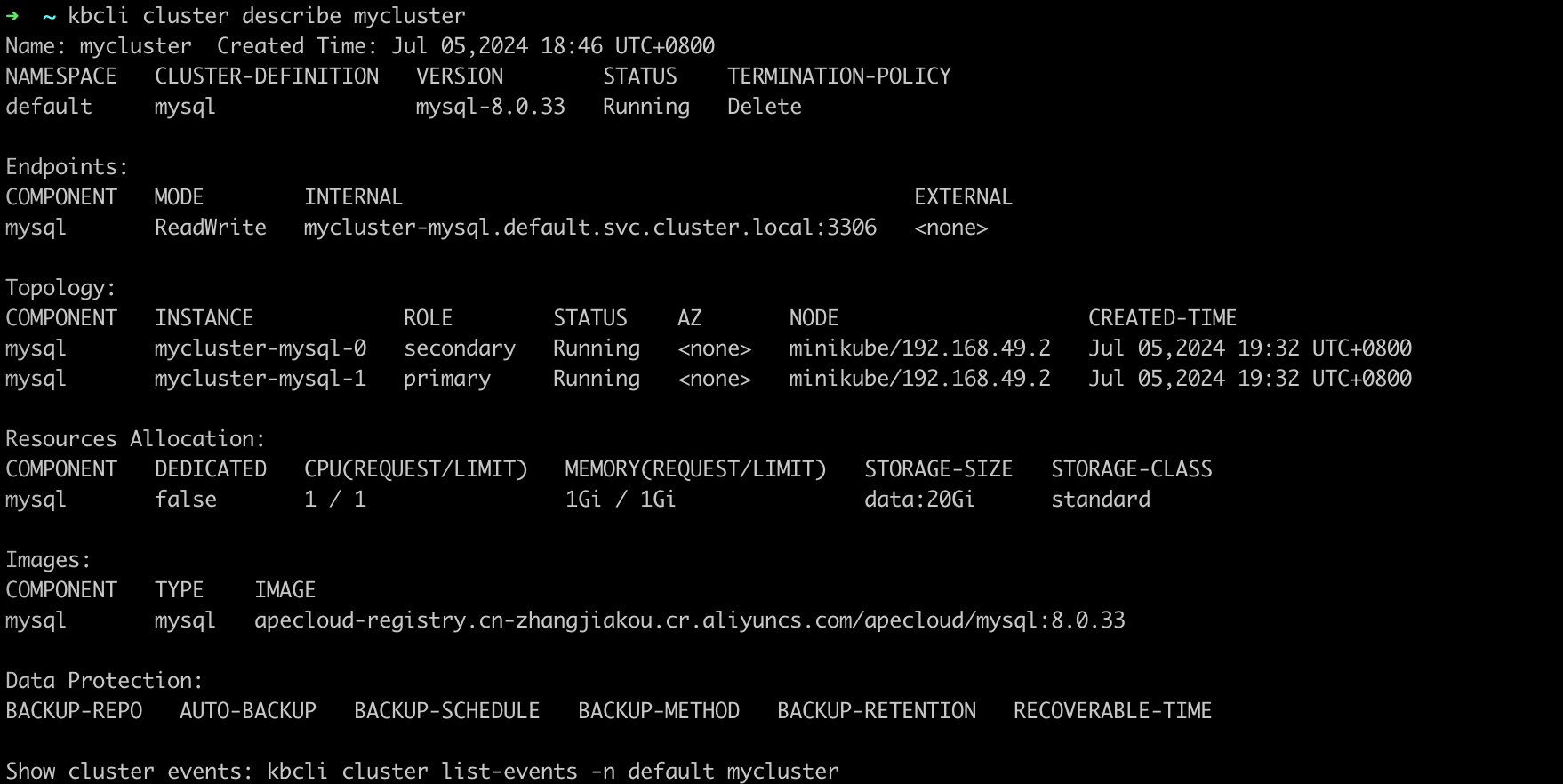
How the automatic recovery works
Every time both pods are deleted, recreation is triggered. And then MySQL automatically completes the cluster recovery and the election of a new primary pod. Once a new primary pod is elected, KubeBlocks detects this new pod and updates the access link. This process takes less than 30 seconds.