This blog is part of our ongoing series about running Microsoft SQL Server. Check out these related articles if you are looking for a way to run MSSQL on Kubernetes using an operator. More blogs about MSSQL on Kubernetes will be published soon.
KubeBlocks can be used as an optional alternative to dedicated operators. For example, Percona XtraDB Cluster Operator (MySQL) and MongoDB Community Kubernetes Operator (MongoDB) are popular dedicated operators that KubeBlocks can complement or replace depending on operational preferences.
Microsoft SQL Server (MSSQL) is a relational database management system developed by Microsoft. Initially supporting only Windows platforms, MSSQL began supporting Linux systems starting with the 2017 version, which made operator-based deployment of MSSQL on Kubernetes possible.
MSSQL provides a multi-database replication management feature called Availability Group (AG), which supports implementing multi-replica redundancy across multiple nodes, thereby improving data reliability and service continuity. On Windows platforms, MSSQL achieves complete high-availability capabilities through integration with Windows Server Failover Cluster (WSFC).
On Linux platforms, MSSQL provides an alternative solution based on Pacemaker + Corosync to build high-availability architecture. However, in cloud-native and operator-based scenarios, Microsoft has not yet provided corresponding high-availability solutions, and currently recommends using the third-party commercial solution DH2I for implementation.
When KubeBlocks integrates MSSQL, it faces the choice of how to build high-availability capabilities on its platform. There are mainly two implementation paths:
The first solution is to build a "rich container" architecture based on Pacemaker, packaging components like Pacemaker, Corosync, and MSSQL together. The advantage is that it can reuse existing open-source components without additional development work; however, the disadvantages include higher operational complexity, more cumbersome configuration of Pacemaker and Corosync, and in operator-managed environments where Pod stability cannot be completely guaranteed, it may lead to high management costs for the overall high-availability system and difficulty ensuring stability.
The second solution is to independently develop a lightweight, cloud-native-oriented distributed high-availability framework to simulate the core functions of WSFC. Although this solution has relatively higher upfront development costs and technical difficulty, it offers higher autonomy and controllability, can avoid dependence on Pacemaker, and provides a more concise and consistent user experience.
Considering that KubeBlocks has already built a unified high-availability management framework-Syncer, new engines only need to implement several key interfaces to quickly complete high-availability capability integration, and the overall development and maintenance costs are within controllable ranges. At the same time, this approach can also provide MSSQL with a high-availability experience consistent with other databases (such as MySQL, MongoDB, etc.).
Therefore, KubeBlocks ultimately chose to implement MSSQL's high-availability capabilities based on the Syncer framework.
Syncer is a lightweight distributed high-availability service independently developed to address database high-availability challenges in cloud-native environments. Its core goal is clear: to make databases in cloud-native environments scheduled and managed uniformly like other stateful services, without requiring developers or operators to deeply understand their internal complex state transitions and data synchronization mechanisms. It not only improves system observability and maintainability but also significantly lowers the threshold for database high-availability feature development.
As a universal component oriented towards multiple database engines, Syncer abstracts a set of standardized high-availability interfaces, including:
Promote: Promote a replica to primary nodeDemote: Demote a primary node to replicaHealthCheck: Health checkThese interfaces enable different types of databases to quickly integrate with Syncer and obtain consistent high-availability support by implementing only a small amount of adaptation logic.
This is also an important reason why we chose the self-developed approach in KubeBlocks for MSSQL. With the basic framework provided by Syncer, we can more flexibly adapt to MSSQL's characteristics, avoid dependence on complex external HA components (such as Pacemaker), and thus build a more lightweight, controllable, and stable cloud-native high-availability solution.
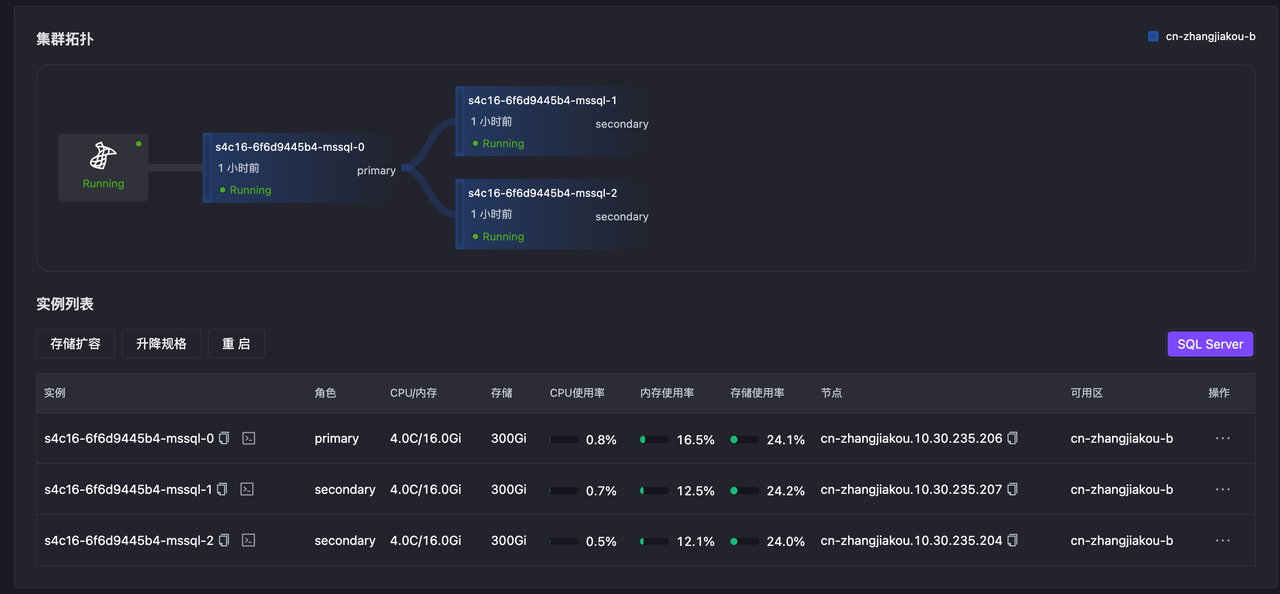
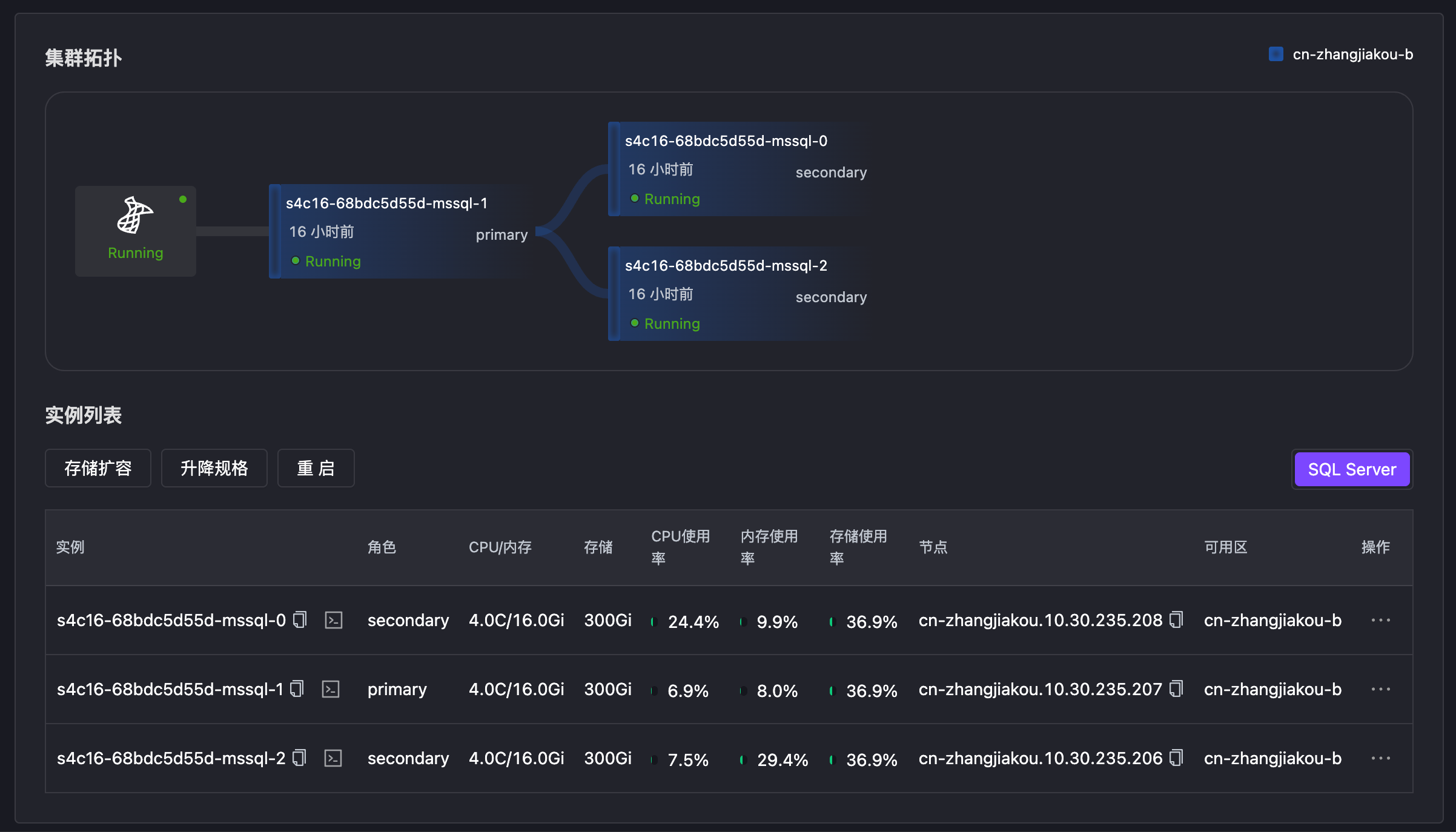
The diagram below shows the high-availability structure of MSSQL with three nodes. KubeBlocks for MSSQL supports up to 5 synchronous nodes, with a maximum of no more than 9 nodes, consistent with the official specifications.
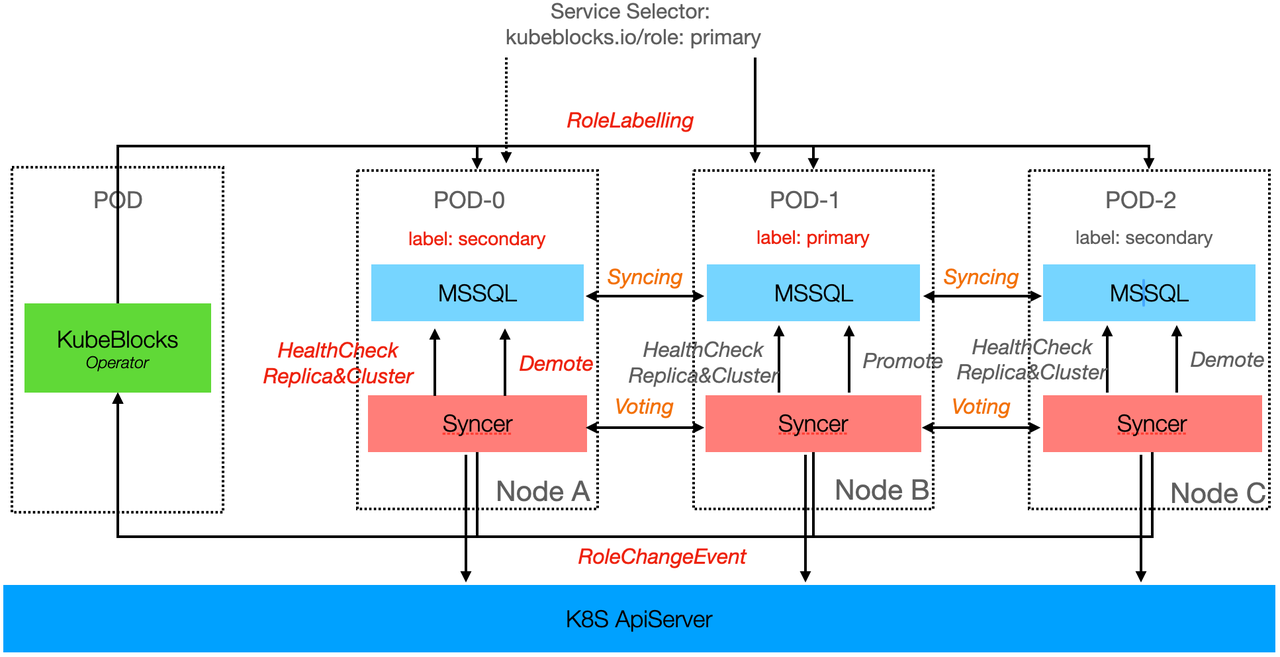
Syncer adopts a distributed architecture design, running as a hypervisor on each database Pod, responsible for local node and cluster-wide health detection. High-availability services between different clusters are independent of each other, each managing replica roles through internal election mechanisms.
On Kubernetes, Syncer uses the API server as a distributed lock mechanism, combined with node heartbeat information and status, to manage node roles. When the primary node becomes abnormal, Syncer triggers failover, selecting the node with the best status from existing healthy nodes to promote to the new primary. When the old primary node recovers, it automatically demotes to a secondary node.
Syncer uses local detection methods, which can discover anomalies more accurately and quickly, unaffected by Kubernetes network fluctuations. At the same time, it can also make more reliable judgments by combining system information:
This comprehensive detection mechanism combining database status with system resources significantly improves the accuracy of fault identification.
Syncer also has certain self-healing capabilities. When a node experiences anomalies such as data corruption, after completing Failover, Syncer can automatically rebuild the replica of that node, ensuring the cluster returns to a healthy state. The entire process requires no manual intervention.
In addition to high availability capabilities, Syncer also provides process hosting and some basic operational support, facilitating fine-grained management in cloud-native environments.
For example, databases typically need to wait for transactions to end and complete flush operations when shutting down. In Kubernetes, Pods can only set termination wait time, and processes will be forcibly closed after timeout, potentially causing data inconsistency issues.
When Syncer performs shutdown operations, it waits for the database to exit normally before reporting stop status, thus avoiding risks from directly killing processes and ensuring database safety and consistency.
After integrating with Syncer, MSSQL on the KubeBlocks platform gained high-availability capabilities close to those of MySQL, PostgreSQL, MongoDB, and other databases, achieving a consistent high-availability experience within a unified framework.
To verify whether MSSQL's high-availability mechanism meets expectations, we conducted comprehensive fault simulation testing. To make the test environment closer to real business scenarios, we imported 90GB of test data before testing and maintained a service performing continuous writes throughout the testing process to simulate actual load.
Due to space limitations, this article only lists several typical fault scenarios for illustration. The complete fault testing report can be obtained from the KubeBlocks official website.
In daily operations, such as during node upgrades or maintenance, it's usually necessary to actively initiate instance role switching (Switchover) to operate nodes in a rolling manner, thereby minimizing database unavailability time. Switchover can transform unexpected faults into controllable operational events, and is a key operation for ensuring high-availability and system maintainability.
Switchover supports operation through the console interface, and can also be performed by issuing an OpsRequest. Under normal circumstances, role switching takes about 10 seconds. Before the new primary node resumes normal access, it needs to complete restoration of all databases in the Availability Group, so the actual data access time will be affected by data volume and current business load.
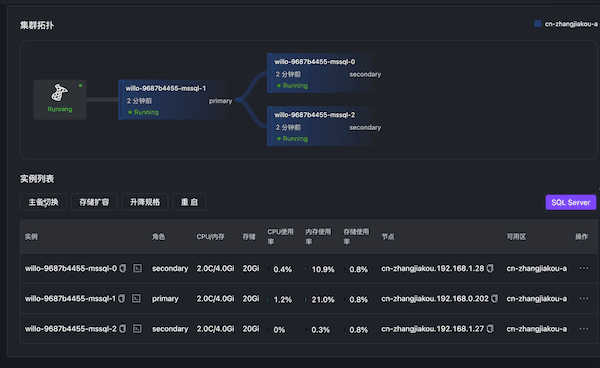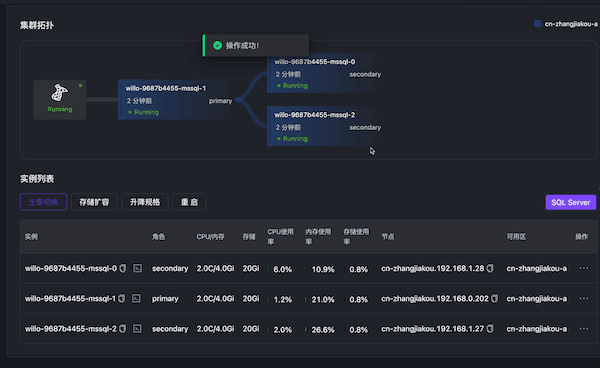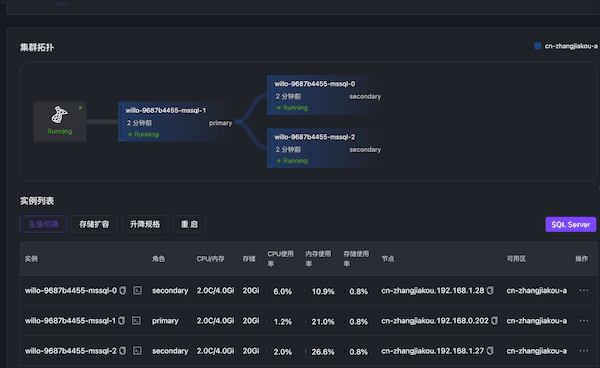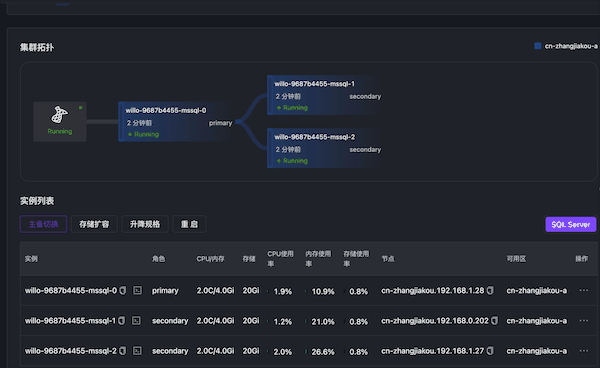
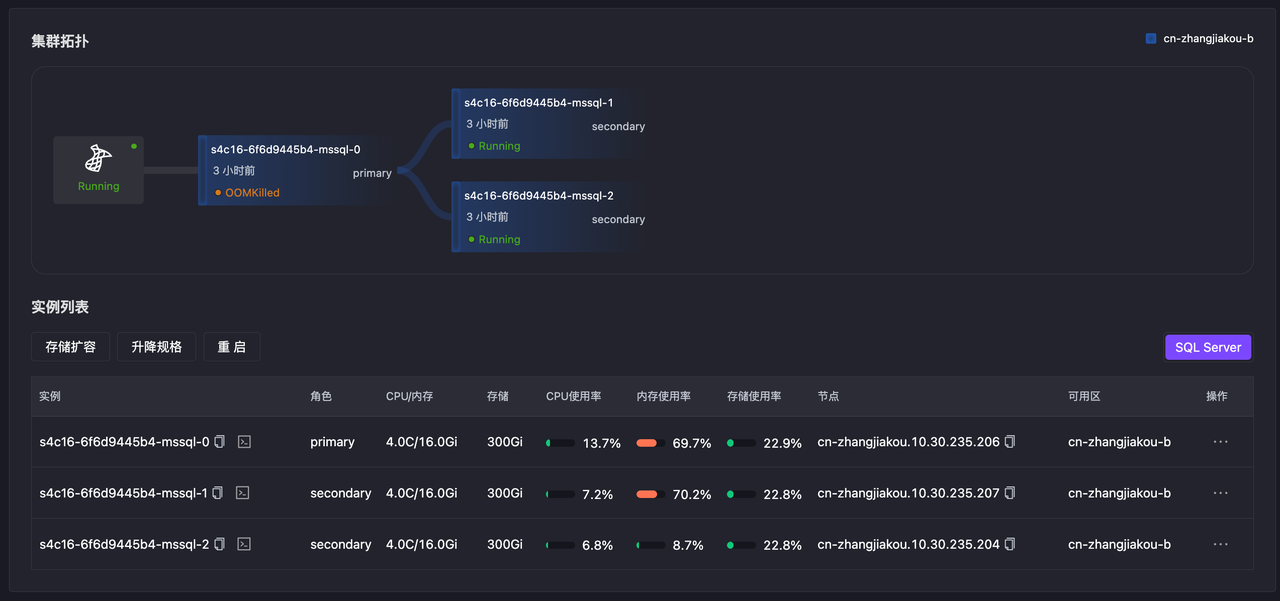
Simulate primary node memory OOM through Chaos Mesh. The database becomes inaccessible, primary-secondary switching occurs, and primary node switching succeeds in about 15 seconds.
kubectl create -f -<<EOF
kind: StressChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
generateName: test-primary-memory-oom-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-757b5769d7
kubeblocks.io/role: primary
mode: all
containerNames:
- mssql
stressors:
memory:
workers: 1
size: "100GB"
oomScoreAdj: -1000
duration: 30s
EOF
kubectl get pod -w -n kubeblocks-cloud-ns s4c16-757b5769d7-mssql-0
NAME READY STATUS RESTARTS AGE
s4c16-757b5769d7-mssql-0 3/4 OOMKilled 1 (2m21s ago) 4h3m
s4c16-757b5769d7-mssql-0 2/4 OOMKilled 1 (2m23s ago) 4h3m
s4c16-757b5769d7-mssql-0 2/4 CrashLoopBackOff 1 (5s ago) 4h3m
s4c16-757b5769d7-mssql-0 3/4 Running 2 (16s ago) 4h3m
s4c16-757b5769d7-mssql-0 4/4 Running 2 (30s ago) 4h3m
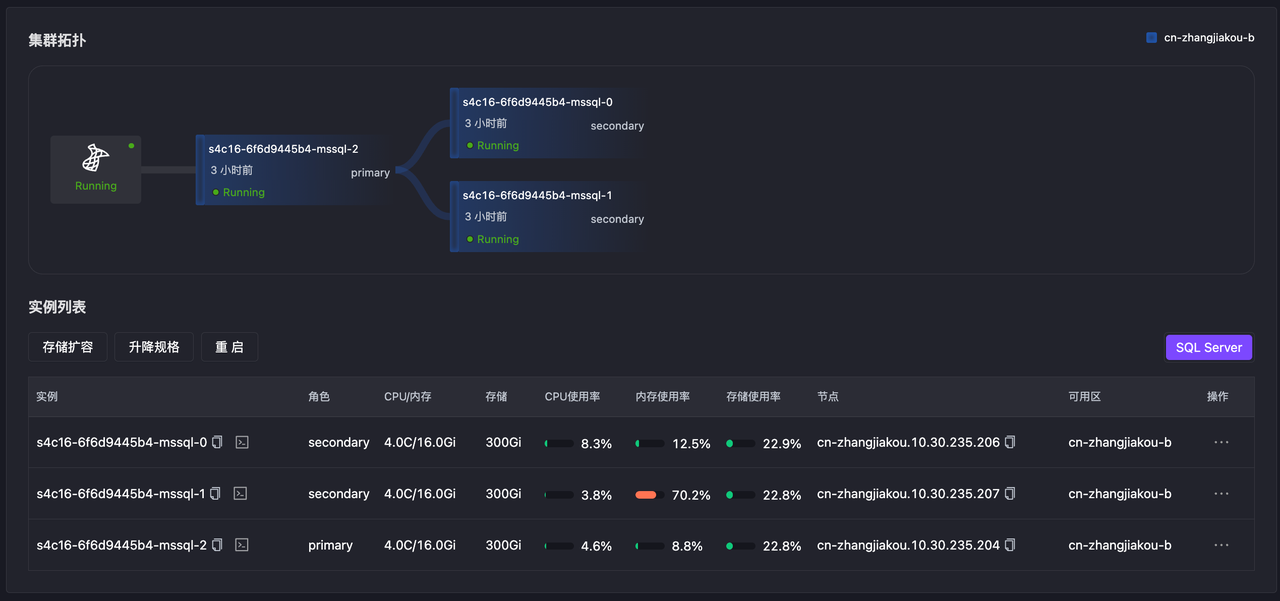
Simulate primary node Pod Failure through Chaos Mesh, causing database inaccessibility and triggering Failover. Primary node switching succeeds in about 1 second.
kubectl create -f -<<EOF
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
generateName: test-primary-pod-failure-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-757b5769d7
kubeblocks.io/role: primary
mode: all
action: pod-failure
duration: 2m
EOF
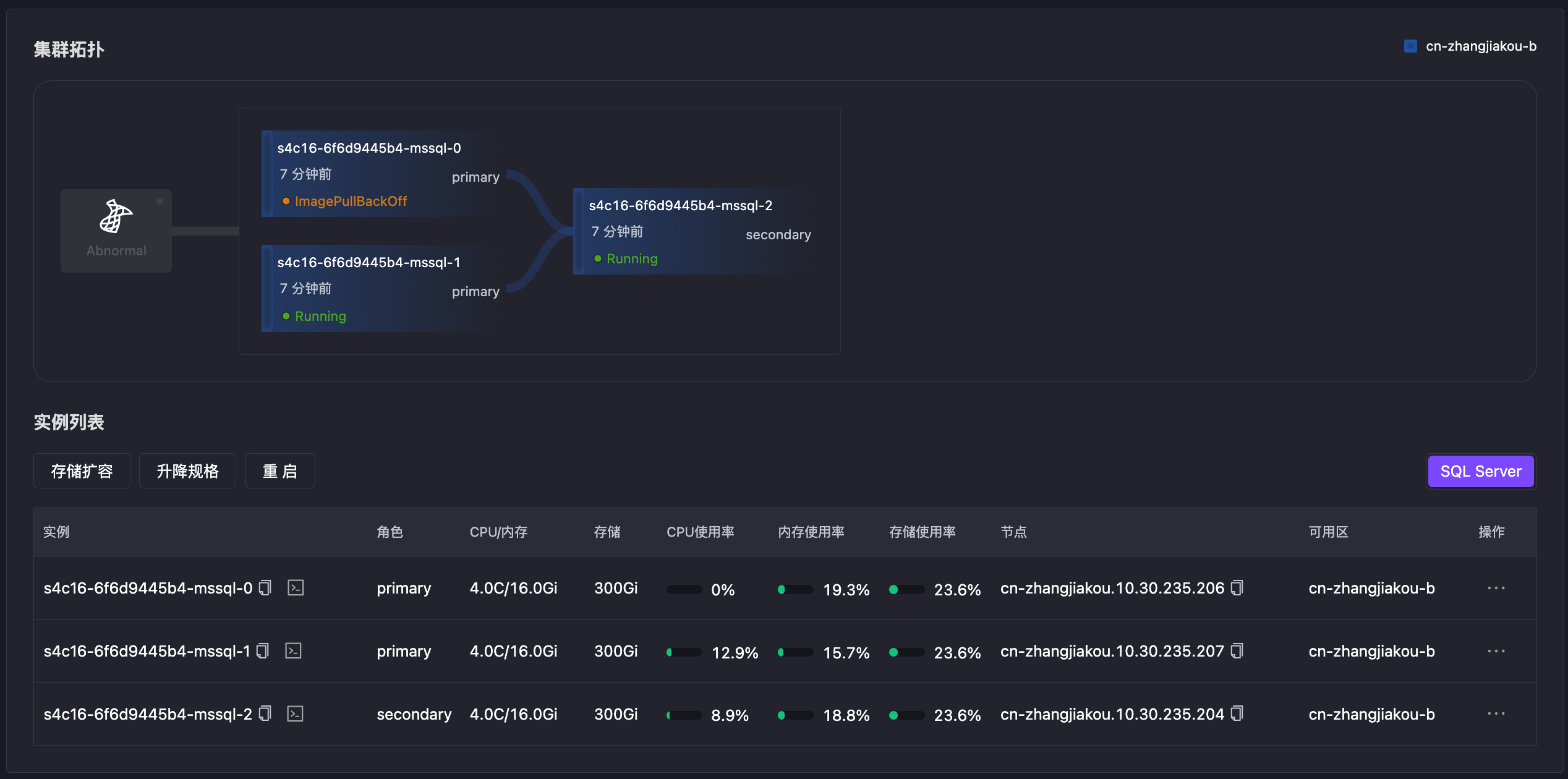
Simulate primary node network delay for five minutes, primary node service becomes inaccessible triggering primary-secondary switching, switching occurs after 15s.
kubectl create -f -<<EOF
kind: NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
generateName: test-primary-network-delay-
namespace: default
spec:
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: s4c16-757b5769d7
kubeblocks.io/role: primary
mode: all
action: delay
delay:
latency: 10000ms
correlation: '100'
jitter: 0ms
direction: to
duration: 5m
EOF
kubectl describe pod -n kubeblocks-cloud-ns s4c16-757b5769d7-mssql-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal checkRole 5m43s lorry {"event":"Success","operation":"checkRole","originalRole":"waitForStart","role":"{\"term\":\"1749106874646075\",\"PodRoleNamePairs\":[{\"podName\":\"s4c16-757b5769d7-mssql-0\",\"roleName\":\"primary\",\"podUid\":\"c3a4f05f-cc25-48ca-9f16-30d4621b7393\"},{\"podName\":\"s4c16-757b5769d7-mssql-1\",\"podUid\":\"b2014bb1-848e-4ebc-900b-e5849b9b0104\"}]}"}
Warning Unhealthy 67s kubelet Readiness probe failed: Get "http://10.30.237.94:3501/v1.0/checkrole": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Kill primary node process 1, simulate process exception triggering Failover, primary node switching succeeds at 1s.
echo "kill 1" | kubectl exec -it $(kubectl get pod -n kubeblocks-cloud-ns -l app.kubernetes.io/instance=s4c16-757b5769d7,kubeblocks.io/role=primary --no-headers| awk '{print $1}') -n kubeblocks-cloud-ns -- bash
kubectl get pod -n kubeblocks-cloud-ns -w s4c16-757b5769d7-mssql-0
NAME READY STATUS RESTARTS AGE
s4c16-757b5769d7-mssql-0 0/4 Error 10 5h30m
s4c16-757b5769d7-mssql-0 0/4 CrashLoopBackOff 10 (5s ago) 5h30m
s4c16-757b5769d7-mssql-0 0/4 CrashLoopBackOff 10 (17s ago) 5h31m
s4c16-757b5769d7-mssql-0 3/4 Running 14 (18s ago) 5h31m
s4c16-757b5769d7-mssql-0 3/4 Running 14 (23s ago) 5h31m
s4c16-757b5769d7-mssql-0 4/4 Running 14 (25s ago) 5h31m
Pacemaker is the recommended high-availability solution for MSSQL on Linux. It is an open-source and mature cluster resource manager widely used for managing various resources in high-availability clusters.
Syncer, as the default high-availability solution provided by KubeBlocks, references Pacemaker in design but is mainly oriented towards cloud-native and operator-based scenarios. To achieve higher levels of high-availability, Syncer adopts Plugin mode in integration, rather than the Agent mode used by Pacemaker. At the same time, Syncer has built-in cluster node management logic, making it more lightweight and efficient in health detection and role switching.
Next, we will specifically compare the capability differences between Pacemaker and Syncer.
In scenarios with only two nodes deployed, Pacemaker has the risk of split-brain. Pacemaker uses a quorum mechanism to ensure clusters can still make consistent decisions when node failures occur: when nodes cannot communicate with each other, the arbitration mechanism is used to determine which nodes can continue providing services to ensure data consistency and availability.
In two-node configurations, two_node mode is usually enabled to maintain high-availability. However, this mode still has the possibility of split-brain and cannot completely avoid this problem.
In contrast, Syncer uses a "heartbeat + global lock" approach to effectively solve the split-brain risk in two-node scenarios. When two nodes cannot communicate, two situations may occur:
This mechanism is not only applicable to two-node scenarios but can also extend to multi-node environments, with good universality and stability.
When the MSSQL primary node becomes abnormal, the high-availability service will trigger failover, selecting the optimal node from healthy secondary nodes to promote to new primary, continuing to provide services externally.
The process of promoting a secondary node to primary node can be divided into two phases:
restore operations on all databases in the AG to bring them into read-write state. The time for this phase is closely related to data volume size and current load conditions, and is not affected by the high-availability service itself.Since this article focuses on comparing the switching capabilities of different high-availability solutions, the test used 10,000 records (a small amount) to reduce the impact of phase 2 on overall results. For high load scenarios and more comprehensive test results, please refer to the complete test report published on the KubeBlocks official website.
| Category | Test Content | pacemaker | syncer |
|---|---|---|---|
| Connection Pressure | Connection Full | No switching | No switching |
| CPU Pressure | Primary node CPU Full | No switching | No switching |
| Secondary node CPU Full | No switching | No switching | |
| Primary and secondary nodes CPU Full | No switching | No switching | |
| Memory Pressure | Primary node memory OOM | RPO=0, RTO=25s | RPO=0, RTO=15s |
| Single secondary node memory OOM | No switching | No switching | |
| Multiple secondary nodes memory OOM | No switching | No switching | |
| Primary and secondary nodes memory OOM | Primary recovers first, no switching | Primary recovers first, no switching | |
| Secondary recovers firstRPO=0, RTO=56s | Secondary recovers firstRPO=0, RTO=33s | ||
| Pod Failure | Primary node Pod Failure | RPO=0, RTO=24s | RPO=0, RTO=1s |
| Single secondary node Pod Failure | No switching | No switching | |
| Multiple secondary nodes Pod Failure | No switching | No switching | |
| Primary and secondary nodes Pod Failure | Primary recovers first, no switching | Primary recovers first, no switching | |
| Secondary recovers firstRPO=0, RTO=54s | Secondary recovers firstRPO=0, RTO=33s | ||
| NTP Exception | Primary node clock offset | No switching | No switching |
| Secondary node clock offset | No switching | No switching | |
| Primary and secondary nodes clock offset | No switching | No switching | |
| Network Failure | Primary node network delay | Short-term delay, no switching | Short-term delay, no switching |
| Long-term delayRPO=0, RTO=37s | Long-term delayRPO=0, RTO=15s | ||
| Single secondary node network delay | No switching | No switching | |
| Multiple secondary nodes network delay | No switching | No switching | |
| Primary and secondary nodes network delay | Primary recovers first, no switching | Primary recovers first, no switching | |
| Secondary recovers first, primary-secondary switchingRPO=0, RTO=28s | Secondary recovers first, primary-secondary switchingRPO=0, RTO=28s | ||
| Primary node network packet loss | RPO=0, RTO=43s | RPO=0, RTO=15s | |
| Single secondary node network packet loss | No switching | No switching | |
| Multiple secondary nodes network packet loss | No switching | No switching | |
| Primary and secondary nodes network packet loss | Primary recovers first, no switching | Primary recovers first, no switching | |
| Secondary recovers firstRPO=0, RTO=82s | Secondary recovers firstRPO=0, RTO=65s | ||
| Kill Process | Primary node process kill | RPO=0, RTO=40s | RPO=0, RTO=1s |
| Single secondary node process kill | No switching | No switching | |
| Multiple secondary nodes process kill | No switching | No switching | |
| Primary and secondary nodes process kill | Primary recovers first, no switching | Primary recovers first, no switching | |
| Secondary recovers firstRPO=0, RTO=74s | Secondary recovers firstRPO=0, RTO=28s |
In cloud-native environments, MSSQL faces many challenges. Since it was originally designed for traditional physical or virtual machine environments, its architecture is not fully adapted to the resource scheduling and operational modes in cloud-native scenarios. Especially in high-availability architecture, limited by differences in resource scheduling methods and difficulty in completely guaranteeing Pod stability, MSSQL's existing high-availability mechanisms are difficult to achieve ideal results.
KubeBlocks for MSSQL was born in this context. It effectively compensates for MSSQL's capability shortcomings in cloud-native scenarios and significantly improves its deployment efficiency and operational management experience. Through integration with Syncer, a lightweight distributed high-availability service, KubeBlocks successfully achieved cloud-native operator-based high-availability support for MSSQL, with stable and efficient performance in fault detection, role switching, self-healing, and other aspects.
Of course, since MSSQL is a closed-source system with relatively limited official technical documentation, deep integration of its high-availability mechanisms faces significant challenges. Currently, we mainly rely on user manuals and database operational experience for derivation, combined with extensive experimental verification to ensure final implementation meets expectations. At the same time, MSSQL's functional modules are relatively closed, with fewer configuration items and status information exposed externally (such as SEED MODE configuration parameters and exception feedback), making system integration and operational management still appear "coarse-grained."
We expect that MSSQL will open more internal configuration options and runtime status metrics in the future to support more fine-grained control and automated management, thereby better adapting to the complex needs of cloud-native platforms.
Finally, KubeBlocks Cloud official website has opened free trial for MSSQL, and also supports multiple mainstream database engines such as MySQL, PostgreSQL, Redis, etc. Welcome to experience and provide valuable suggestions!