This blog is part of our ongoing series about running Microsoft SQL Server. Check out these related articles if you are looking for a way to run operator-based MSSQL on Kubernetes. More blogs about MSSQL on Kubernetes will be published soon.
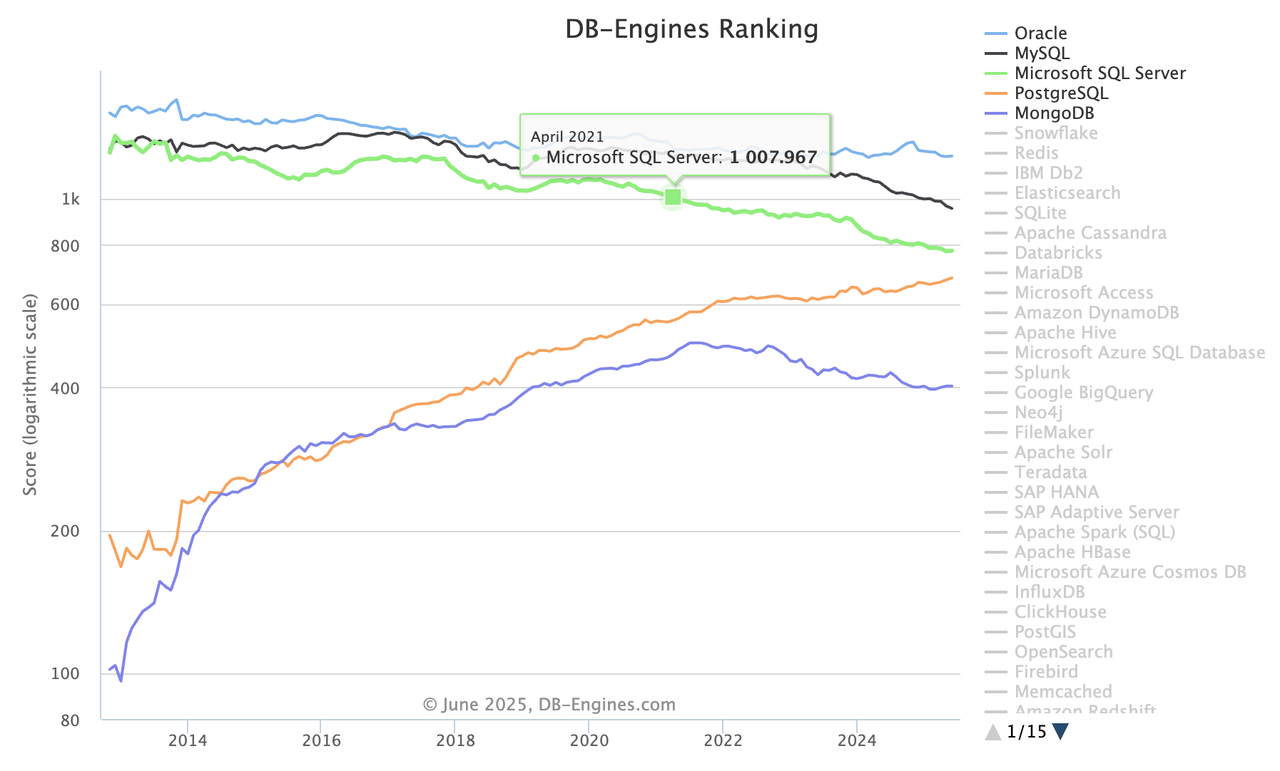
Microsoft SQL Server (MSSQL) is an enterprise-level relational database management system developed by Microsoft. It has a history of over 30 years since its first version, SQL Server 1.0, was released in 1989. According to the DB-Engines Ranking Trend, MSSQL has consistently ranked among the top three globally for the past decade, second only to Oracle and MySQL, making it one of the industry's recognized mainstream database products.
In enterprise production environments, database high availability is a crucial guarantee for business continuity. MSSQL's Always On Availability Group (AG) technology provides enterprises with a mature high-availability solution through multi-replica synchronous replication and automatic failover, effectively preventing data loss and minimizing service downtime. Therefore, Always On AG has become a standard configuration for enterprise-level MSSQL deployments and an indispensable data protection technology for critical business systems.
With the rapid development of cloud-native infrastructure, more enterprises are running MSSQL on Kubernetes using an operator-centric approach. Compared with simply running container images, operatorization embeds domain-aware lifecycle logic, CRD-driven automation, and orchestration workflows that go beyond basic image start/stop semantics. KubeBlocks can be seen as an operator-focused, unified framework for stateful services and is an optional alternative to dedicated, single-engine operators. For MSSQL, community or vendor projects exist with names such as "mssql-operator" or "sqlserver-operator" that aim to provide operator-style management; KubeBlocks offers a more generic, extensible Addon model that can serve as an alternative to those dedicated operators.
Although Microsoft provides deployment guidance for running MSSQL in containers and in Kubernetes, those StatefulSet-based or image-centric deployment approaches are often inadequate for enterprise scenarios with high requirements for availability and business continuity:
Although Always On AG technology is mature in traditional environments, bringing AG into an operatorized Kubernetes environment raises fundamental challenges:
Against this backdrop, KubeBlocks offers an operator-centric solution for running MSSQL Always On AG. This article will introduce how to implement MSSQL operatorization based on the open-source KubeBlocks, including its Addon integration mechanism, the implementation of the MSSQL Always On AG Addon, and finally, a demonstration of actual deployment and operational effects.
KubeBlocks, as an open-source K8s Operator framework designed specifically for stateful applications, enables developers to implement MSSQL operatorization based on a unified abstraction layer and automated operational capabilities. KubeBlocks has the following features:
The plugin-based design of KubeBlocks provides a set of interfaces for us to integrate MSSQL. By implementing these interfaces, KubeBlocks can run and manage MSSQL database clusters on K8s.
These interfaces are like the connection points of Lego bricks: whether it's a block for building a house, a wheel for a car, or an arm for a robot, as long as your studs and sockets conform to the standard Lego specifications, they can connect perfectly with other bricks to build complex creations. Similarly, KubeBlocks defines a standard set of "database brick" interface specifications. Any database that "designs its connection points" according to these specifications can be seamlessly integrated into the KubeBlocks platform and work collaboratively with other components.
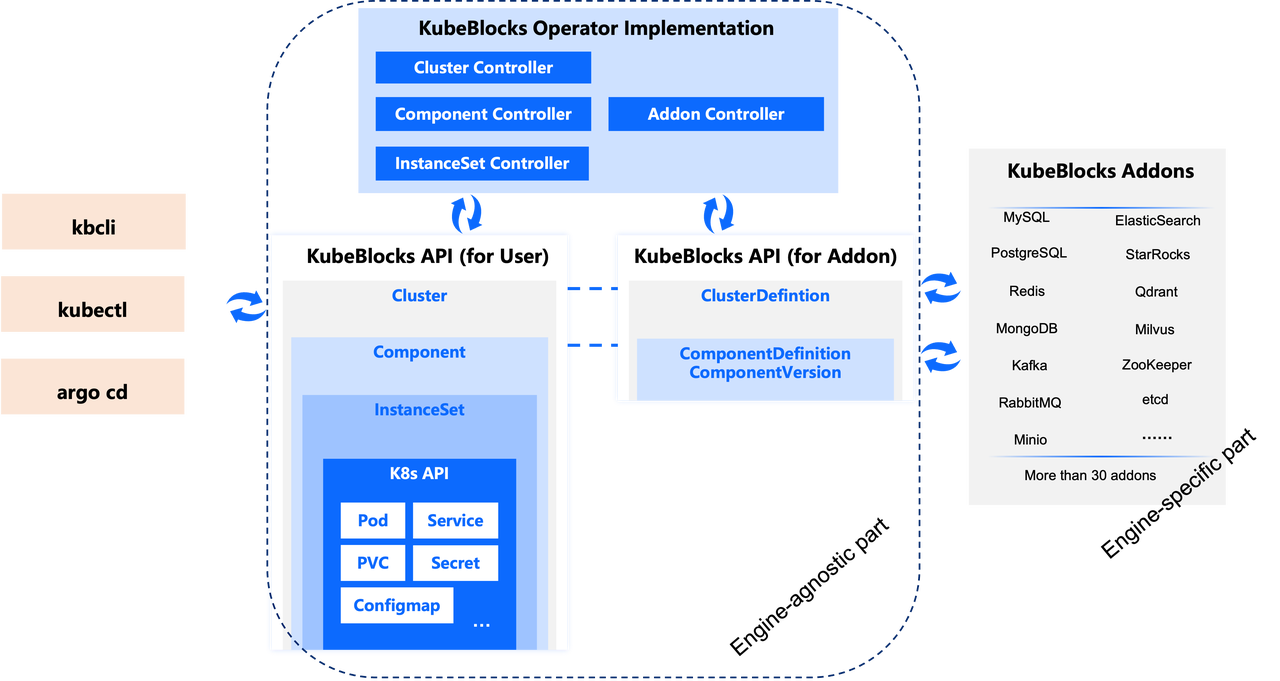
In KubeBlocks, these interfaces correspond to a set of APIs, which are a group of K8s CRD definitions, as shown in the figure below with ClusterDefinition, ComponentVersion, and ComponentDefinition. By defining the corresponding CRs, you can integrate a database engine, which we also call an Addon (plugin). The purpose and description of these interfaces will be introduced in the context of the specific implementation for integrating MSSQL below.
This section describes how we implement features like MSSQL cluster management, high availability, parameter configuration, and backup/restore.
By implementing the following interfaces, you can manage the basic lifecycle and operations of an MSSQL cluster in KubeBlocks:
Here, we will mainly introduce the implementation of ComponentDefinition. Note that the MSSQL Addon described in this article is based on the KubeBlocks 0.9 API.
The ComponentDefinition for MSSQL mainly includes the following parts:
primary and secondary.sa and kbadmin, and their password generation policies. KubeBlocks will generate the corresponding account and password information into the respective secrets.MSSQL_SA_USER for the database cluster system administrator account name, and MSSQL_SERVER_PORT for the service port number. These variables will eventually be rendered as environment variables in the Pod.roleProbe: Used to probe the role of a replica.memberLeave: Used to adjust the topological relationship between replicas during cluster scale-in.init-syncer: Copies necessary tools like Syncer.mssql: The container where the MSSQL service runs.exporter: Used to collect database monitoring metrics.With this, a basic MSSQL component is defined.
Astute readers might wonder, how does the component start the MSSQL service? And how do the multiple replicas of the component form an AG cluster? How are the previously mentioned operatorization challenges for Always On AG overcome?
The key details and complexities lie in the startup script of the mssql container. When the container starts, it first launches the MSSQL process and then executes different flows depending on whether initialization has already been performed. During initialization, the Pod with the smallest serial number is chosen as the primary node, and the remaining Pods become secondary nodes.
The initialization process for the primary node includes the following steps:
kbadmin.The initialization process for secondary nodes is similar, with the difference that they do not create the AG but join the one already created by the primary node. Once all nodes are initialized and have joined the same AG, they form an AG cluster.
However, the AG cluster itself does not have automatic failover capabilities and relies on external components. In a Linux environment, traditional automatic failover typically depends on Pacemaker and Corosync. However, these components are cumbersome to configure in a containerized environment and are not fully adapted to it, leading to high maintenance costs and questionable stability for the overall high-availability system. To address this, we independently developed a lightweight, multi-database engine-supported, cloud-native distributed high-availability component called Syncer. For more details on the high-availability design of KubeBlocks for MSSQL, the specific implementation of Syncer, and how to use Chaos Mesh to improve cluster availability, please refer to KubeBlocks for MSSQL High Availability Implementation.
Database engines usually have many parameters and configurations. Some need to be specified during initialization, some need to be specified in configuration files, some parameter changes require restart to take effect, and some can be modified dynamically. To facilitate integration of different types and formats of database parameter configurations, KubeBlocks defines parameter configuration-related interfaces:
In the MSSQL Addon, according to MSSQL startup requirements, parameter templates are defined to render the mssql.conf configuration file, which MSSQL will use when starting. At the same time, ConfigConstraint is defined to specify its supported configuration file format as ini, as well as dynamic parameters, static parameters, and immutable parameters.
The importance of backup for database systems is self-evident. In case of accidents such as mistaken deletion of databases/tables, hardware failures, natural disasters, etc., data loss and service interruption may occur, affecting online business. Through regular backups and saving backup data to different regions and different storage media, data can be recovered through backup in extreme situations.
KubeBlocks defines two interfaces to implement backup for database systems:
We implemented three backup methods for the MSSQL Addon:
BACKUP LOG command to upload database log files to achieve point-in-time recoveryWith the help of KubeBlocks' abstraction of backup destinations, namely BackupRepo, the above backups can be easily uploaded to object storage provided by mainstream cloud vendors, including object storage services from Alibaba Cloud, Huawei Cloud, Tencent Cloud, AWS, Google Cloud, Microsoft Azure, Oracle Cloud, etc. For on-premise deployment scenarios, it also supports self-deployed storage services such as MinIO, XSKY, NAS, etc.
Now, let's actually deploy an MSSQL Always On AG cluster and perform some operational change operations. (Note: The MSSQL Addon is currently only available in the enterprise edition and has not been open-sourced yet)
Create a three-replica MSSQL cluster by applying a cluster YAML file with kubectl command.
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: Cluster
metadata:
name: my-mssql
annotations:
kubeblocks.io/extra-env: '{"MSSQL_PID":"Developer","MSSQL_COLLATION":"SQL_Latin1_General_CP1_CI_AS"}'
spec:
terminationPolicy: Delete
clusterDefinitionRef: mssql
componentSpecs:
- name: mssql
serviceVersion: 2022.19.0
replicas: 3
resources:
limits:
cpu: "1"
memory: "2Gi"
requests:
cpu: "1"
memory: "2Gi"
volumeClaimTemplates:
- name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
EOF
Check the cluster and pod status:
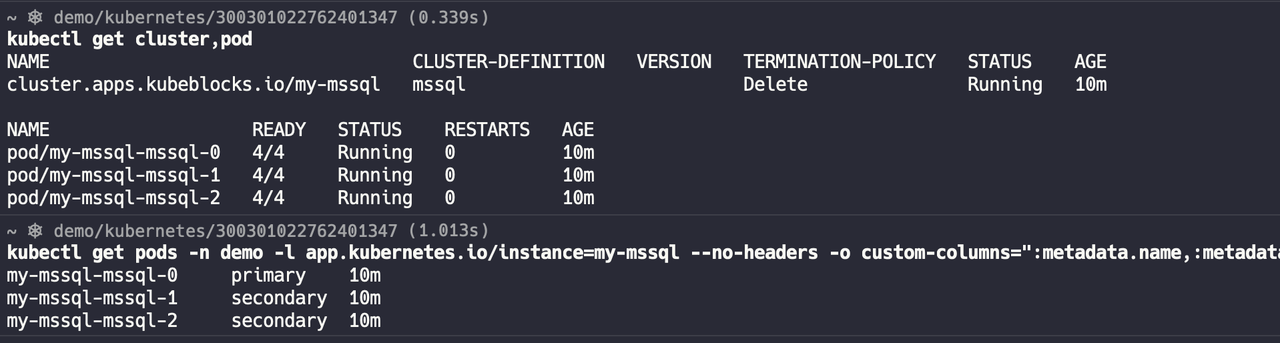
Simulate node failure by deleting a pod to check if roles automatically switch. As shown below, after deleting the current primary node my-mssql-mssql-0, my-mssql-mssql-1's role changes to primary within a few seconds.
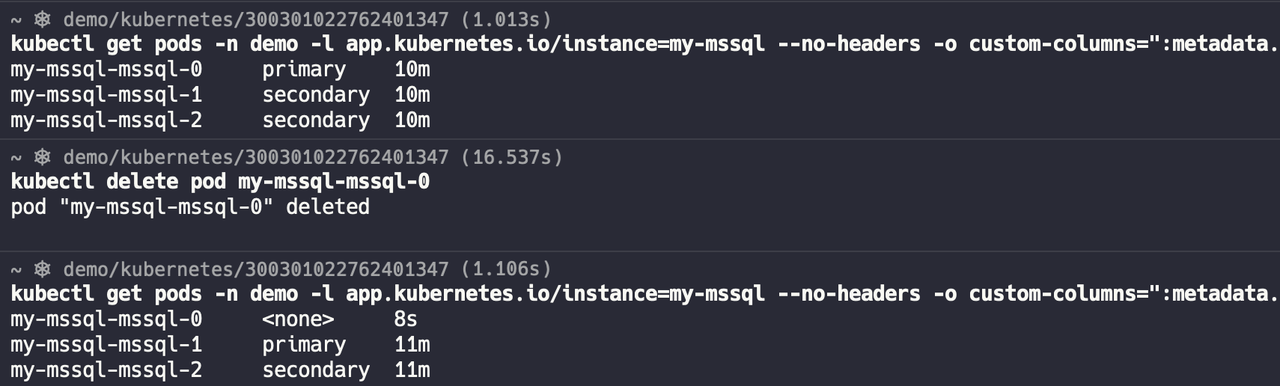
Subsequently, the my-mssql-mssql-0 node's role changes to secondary, joining the cluster as a new secondary node.

Execute the following OpsRequest to scale cpu/memory from 1C2G to 2C4G.
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: OpsRequest
metadata:
name: ops-vertical-scaling
spec:
clusterName: my-mssql
type: VerticalScaling
verticalScaling:
- componentName: mssql
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
EOF
Check the cluster status and Pod status, wait for the change to complete, and check Pod resources.
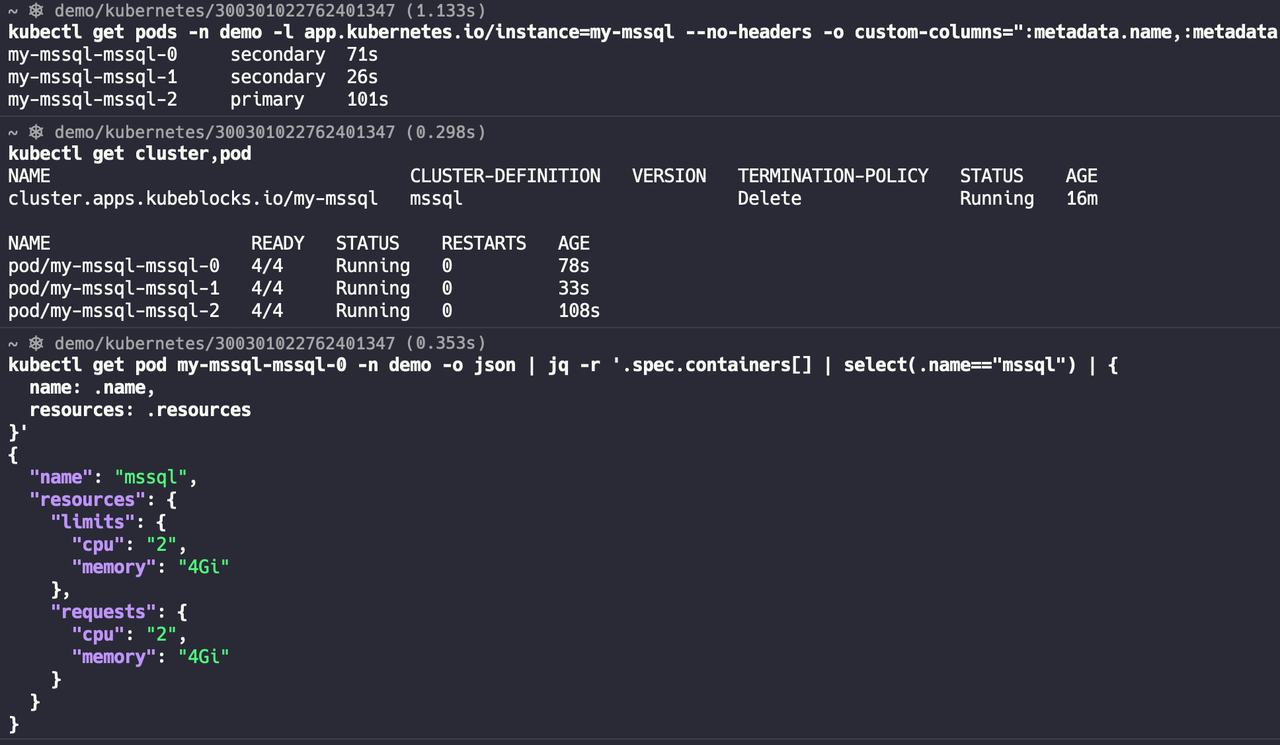
Execute the following command to create a full backup:
kubectl apply -f - <<EOF
apiVersion: dataprotection.kubeblocks.io/v1alpha1
kind: Backup
metadata:
name: mssql-cluster-backup
spec:
backupMethod: full
backupPolicyName: my-mssql-mssql-backup-policy
deletionPolicy: Delete
EOF
Check the backup as follows:

Restore a brand new cluster based on this backup:
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: OpsRequest
metadata:
name: mssql-cluster-restore-ops
spec:
clusterName: my-mssql-restored
force: false
restore:
backupName: mssql-cluster-backup
backupNamespace: demo
type: Restore
EOF
opsrequest.apps.kubeblocks.io/mssql-cluster-restore-ops created
Check the status of the restored cluster:
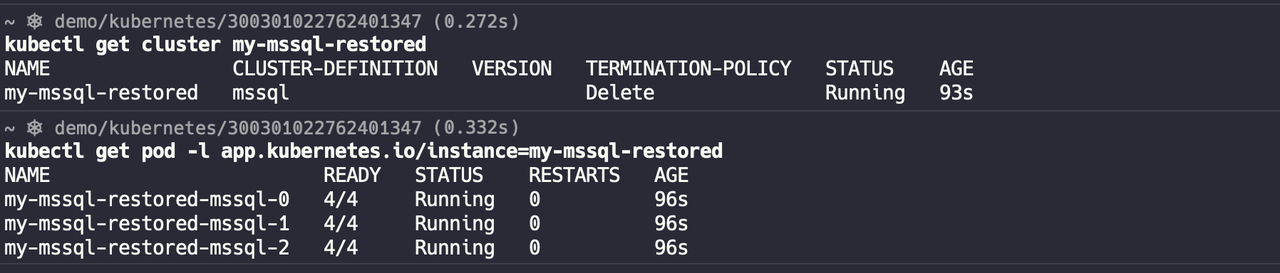

After integrating with KubeBlocks in Addon form, it naturally supports many cluster operational operations. Besides the automatic failover, vertical scaling, and backup and recovery introduced above, it also supports the following operational operations:
Running MSSQL in cloud-native environments faces many challenges. KubeBlocks, as an open-source K8s Operator framework designed specifically for stateful applications, provides strong support for operator-based MSSQL deployments. This article detailed how to implement an MSSQL Addon supporting Always On AG based on open-source KubeBlocks and demonstrated its advantages in operatorized deployment, high availability, and automated operations. Currently, KubeBlocks for MSSQL has been launched in KubeBlocks Enterprise Edition. Interested readers are welcome to apply for experience.
Although KubeBlocks has solved many key problems of MSSQL Always On AG operatorization, it still faces some challenges in enterprise application scenarios, such as existing tool ecosystem integration, AD domain integration, etc., which we are actively solving and improving. We believe that by continuously solving these practical pain points in enterprise scenarios, operatorized MSSQL will truly become a trusted choice for enterprise data management.