Oracle Data Guard (DG for short) is a high availability and disaster recovery solution provided by Oracle. It provides a complete set of services for maintaining, managing, and monitoring one or more standby databases, enabling Oracle databases to withstand disasters and data corruption. DG maintains these standby databases as replicas of the production database. When the production database becomes unavailable due to planned or unplanned outages, DG can switch any standby database to the production role, thereby minimizing downtime caused by interruptions.
KubeBlocks is an open-source Operator that supports multi-engine management, running and managing multiple database engines on K8s through unified code and APIs. New engines can be added by simply writing KubeBlocks Addons. At its core, KubeBlocks is a K8s Operator that defines a set of CRs to abstract common attributes of various database engines and uses these abstractions to manage the engine lifecycle and daily operations.
Oracle has provided images from 11g to 23ai free versions and has open-sourced the official Oracle Database Operator. However, merely providing images and a container runtime (i.e., image + containerd start/stop) does not solve higher-level lifecycle and day-2 management needs. Operator-level orchestration, richer Addon integrations, and unified APIs are required. In operator-managed Kubernetes environments, the following limitations and challenges are commonly encountered:
Taking Oracle 12c as an example, although its deployment and operations in traditional environments are quite mature, migrating to operator-managed Kubernetes environments still requires overcoming many issues:
Addressing the above current state and challenges, this article will leverage KubeBlocks capabilities to demonstrate how KubeBlocks solves these pain points and explore some details of Oracle database operatorization via the KubeBlocks Addon model, understanding the design philosophy and implementation mechanisms of KubeBlocks and Addons.
First, with a practical operation example, this article will demonstrate the process of creating an Oracle 12c DG cluster and some operational operations. The example cluster architecture is as follows:
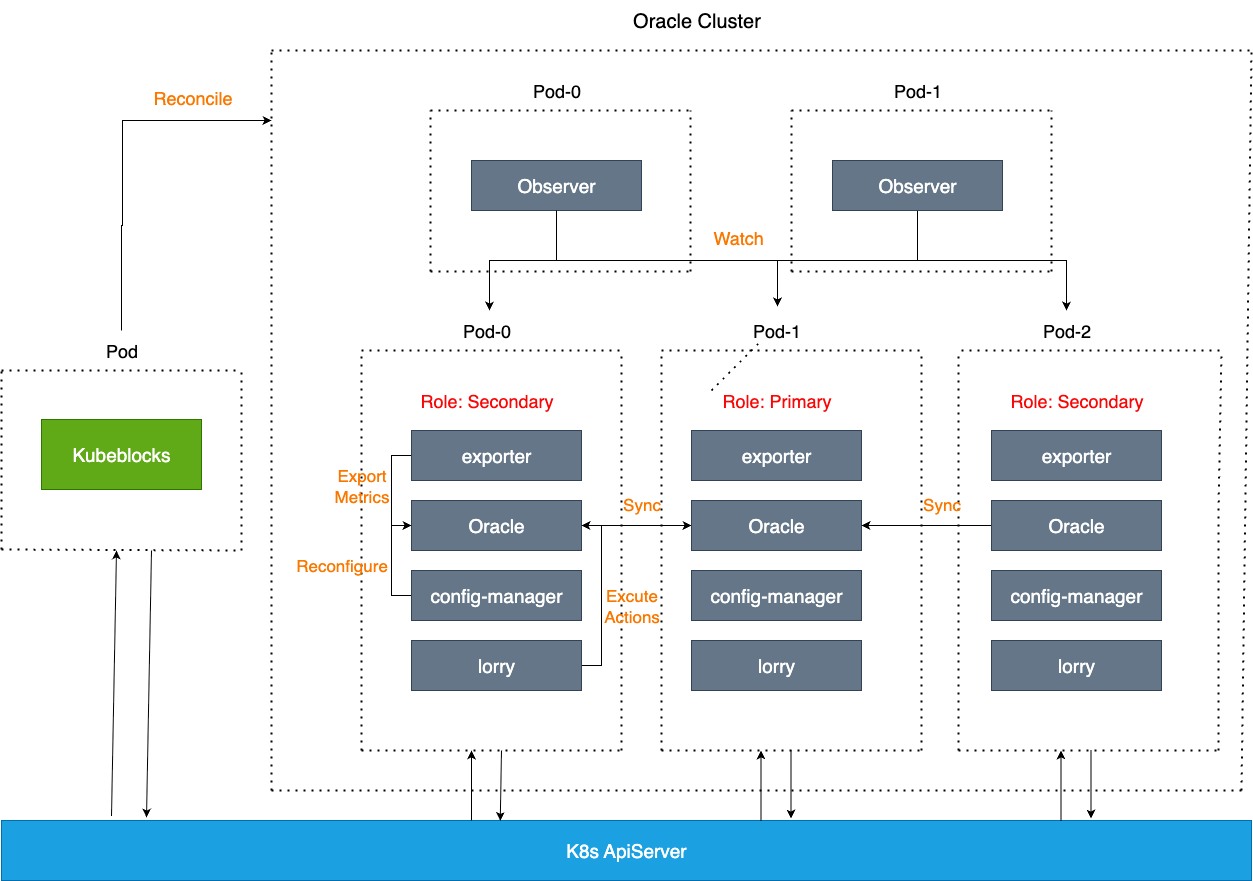
Using kubectl apply with the following Cluster YAML will create a cluster with one primary, two standbys, and two Observer nodes:
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: Cluster
metadata:
name: my-oracle
labels:
helm.sh/chart: oracle-cluster-0.9.0
app.kubernetes.io/name: oracle-cluster
app.kubernetes.io/instance: my-oracle
app.kubernetes.io/version: "12.2.0.1"
app.kubernetes.io/managed-by: Helm
spec:
clusterDefinitionRef: oracle
terminationPolicy: Delete
topology: replication
affinity:
podAntiAffinity: Preferred
topologyKeys:
- kubernetes.io/hostname
tenancy: SharedNode
componentSpecs:
- name: oracle
replicas: 3
componentDef: oracle-12c
monitor: true
disableExporter: false
serviceVersion: 12.2.0
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "1"
memory: "1Gi"
volumeClaimTemplates:
- name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
- name: fra
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
- name: observer
replicas: 2
componentDef: oracle-observer-12c
serviceVersion: 12.2.0
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "0.5"
memory: "0.5Gi"
EOF
As you can see in the above Cluster, it specifies the components of this cluster and some related definitions. Even readers who haven't previously worked with KubeBlocks can get a relatively intuitive understanding of this cluster through the descriptive API fields (key API fields will be explained in detail later). After applying, a complete Oracle 12c DG cluster is created. Check the cluster and pod status:
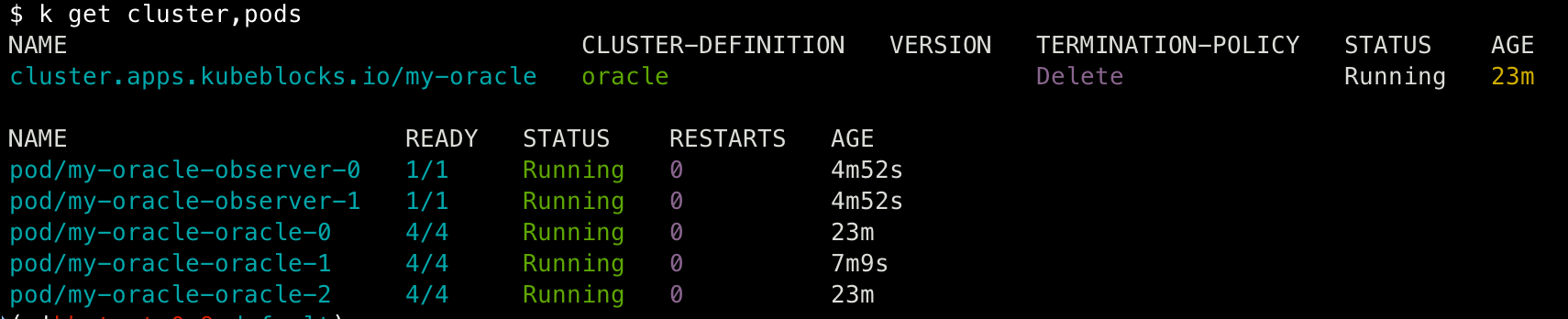

You can see that observer-related pods have no roles, while oracle-related pods are set as primary or secondary. Roles are very important in stateful clusters managed by KubeBlocks. They not only represent the replication relationships between database instances but also represent KubeBlocks' abstraction of these relationships. These relationships directly affect KubeBlocks' behavioral expectations in various operational operations.
Using sqlplus to check the Oracle parameter open_cursors, we find the value is 300:
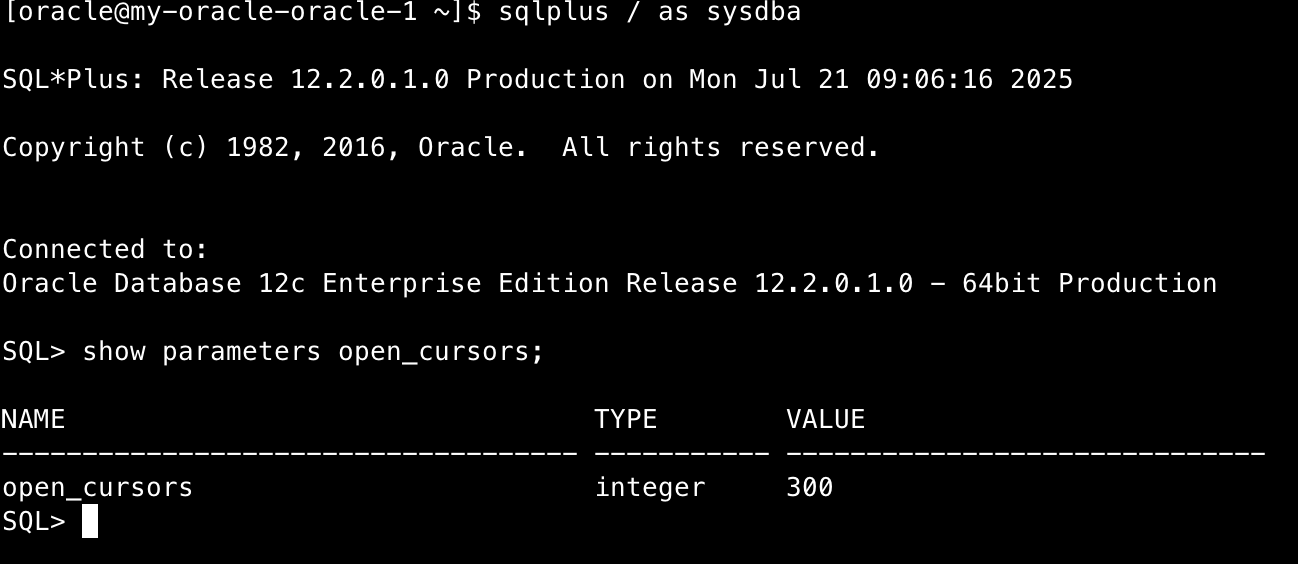
Apply the following OpsRequest YAML using kubectl apply:
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: OpsRequest
metadata:
name: my-oracle-reconfiguring
namespace: default
spec:
clusterName: my-oracle
force: false
reconfigure:
componentName: oracle
configurations:
- keys:
- key: init.ora
parameters:
- key: open_cursors
value: '301'
name: oracle-config
preConditionDeadlineSeconds: 0
type: Reconfiguring
EOF
Checking the parameter open_cursors again, we find the value has been successfully changed to 301:

Oracle's Fast-Start Failover feature enables automatic failover to a standby database when the primary database fails, ensuring quick and reliable business recovery. By deleting pods to simulate node failure, we can check if the Oracle standby node is automatically promoted to primary. For example, when deleting the current primary node my-oracle-oracle-0, after a few seconds, my-oracle-oracle-1's role changes to primary, while my-oracle-oracle-0 rejoins the cluster with a secondary role.

During this process, KubeBlocks continuously maintains role detection for Oracle to ensure the service cluster state recovers quickly and provides normal external services.
Additionally, KubeBlocks designs various abnormal scenarios for supported databases using Chaos Mesh to verify database high availability. For details, see: Practical Experience in Validating KubeBlocks Addon Availability with Chaos Mesh.
Backup is key to data protection. In KubeBlocks, using predefined backup methods, you can create a full backup by simply applying the following YAML:
kubectl apply -f - <<EOF
apiVersion: dataprotection.kubeblocks.io/v1alpha1
kind: Backup
metadata:
name: my-oracle-cluster-backup
spec:
backupMethod: oracle-rman
backupPolicyName: my-oracle-oracle-backup-policy
deletionPolicy: Delete
EOF
This will call Oracle's rman tool to perform a full backup of the current cluster and upload the resulting backup to the specified storage.
View the backup as follows:

After obtaining this complete backup, you can restore a brand new cluster based on this backup, again with just a simple YAML:
kubectl apply -f - <<EOF
apiVersion: apps.kubeblocks.io/v1alpha1
kind: OpsRequest
metadata:
name: my-oracle-cluster-restore
spec:
clusterName: my-oracle-restored
force: false
restore:
backupName: my-oracle-cluster-backup
backupNamespace: default
type: Restore
EOF
Check the status of the restored cluster:
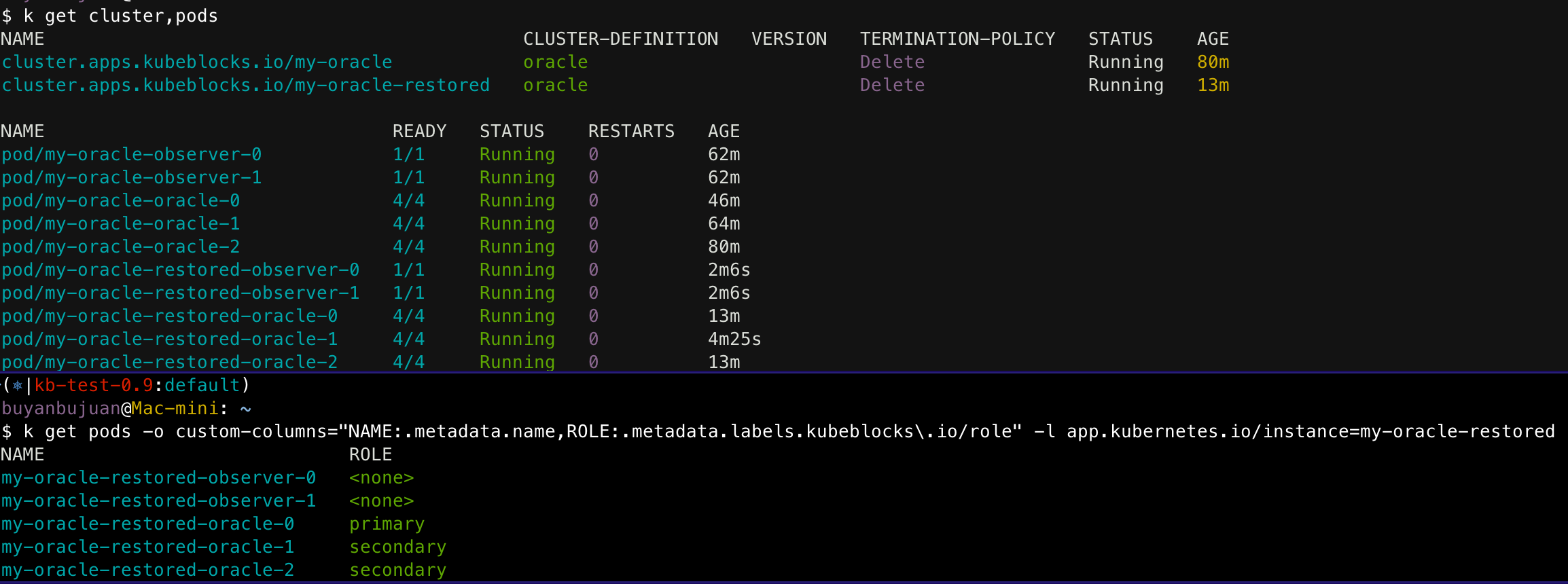
This completes the backup and recovery operation. You can also define backup frequency, timing, and other strategies.
After integrating with KubeBlocks, Oracle Addon naturally supports many other operations. In addition to the automatic failover, configuration changes, and backup recovery introduced above, it also supports the following operations:
How is such a complete Addon implemented? The following will introduce some APIs in detail to help understand the principles and design philosophy. Readers can read this part together with the operational examples. For more detailed API interpretation, you can directly check the API annotation section in the KubeBlocks source code.
KubeBlocks can conveniently extend its functionality through the Addon mechanism, supporting multiple databases and middleware. For detailed documentation, refer to: KubeBlocks Addon Documentation
KubeBlocks provides a set of abstract APIs for defining and managing database instances. Oracle Addon is based on these APIs, providing a complete solution for Oracle DG clusters.
Oracle Addon mainly defines cluster-level lifecycle management and operations through 3 CRs:
Among the above 3 CRs, the most important and complex CR is CMPD. Like using LEGO blocks to build models, as long as you have basic blocks (Components), you can build various complex models (Clusters).
Oracle's CMPD mainly includes the following parts:
ORACLE_SYS_USER and password ORACLE_SYS_PASSWORD defined in systemAccounts, and the connection strings ALL_ORACLE_FQDN for all Oracle replicas in the entire cluster. Based on these vars, Oracle's TNS and listener configurations can be completed.In addition to the explicitly defined containers above, KubeBlocks will also inject two sidecar containers for each Pod:
After completing the above core configurations and some related configurations, a complete Oracle component is defined. For the Observer component, it can be defined in the same way. After both components are defined, the complete topology of the entire cluster can be completed through CD.
How does Oracle Addon complete the configuration between primary and standby nodes in a DG cluster? The logic related to node initialization is completed in Oracle's startup script. Initially, some general initialization operations are performed based on cluster specifications and configuration information, such as adjusting kernel parameters based on instance specifications, setting listeners, and configuring TNS. Then different operations are performed based on the node's role: if it's a primary node, the DBCA tool is used to create the database; if it's a standby node, the RMAN tool is used to recover the database from the primary node.
After both primary and standby nodes are set up, the postProvision lifecycleAction mentioned earlier is used to complete the DG Broker configuration between primary and standby nodes, creating and enabling the DG Broker Configuration. At this point, the Oracle Component is built.
Finally, KubeBlocks creates the Observer Component according to the Order configured in CD, configuring Fast-Start Failover (FSFO) for the cluster, and only then is the entire cluster creation complete.
At this point, the cluster has high availability. When the primary node fails, the Observer will detect the anomaly and trigger failover, promoting the standby node to primary, thus ensuring business continuity.
To facilitate parameter management for various databases, KubeBlocks defines parameter configuration-related APIs:
Oracle mainly uses pfile and spfile to configure database parameters. To facilitate user configuration, Oracle Addon sets some parameters from pfile to KubeBlocks' parameter template. After the instance starts, spfile is generated based on this dynamically rendered pfile.
Backup and recovery are important aspects of database operations. KubeBlocks provides flexible backup-related APIs for various databases to implement different backup and recovery mechanisms, including full backup, incremental backup, and point-in-time recovery. Addons only need to implement the following two APIs:
Taking the full backup implemented in Oracle Addon as an example, an ActionSet named oracle-rman is defined with a backupType of Full, indicating this is a full backup. Then a BackupPolicyTemplate named oracle-backup-policy-template is defined, which specifies using the oracle-rman ActionSet for full backup and sets the default backup scheduling cycle through a Cron expression. With these definitions, KubeBlocks can automatically execute backups and upload them to specified storage locations, which can be local storage or cloud storage services like AWS S3.
Running Oracle clusters stably and efficiently in Kubernetes environments is not simple, but KubeBlocks provides an insightful and effective solution. This article detailed the specifics of supporting Oracle Addon based on the KubeBlocks Operator and introduced its supported features and advantages. Currently, KubeBlocks for Oracle has been launched in KubeBlocks Enterprise Edition. Interested readers are welcome to apply for a trial.
We will continue to optimize and iterate KubeBlocks for Oracle to support more features and improve stability, while also adding support for more Oracle versions, making KubeBlocks for Oracle the best choice for more enterprise users.