Milvus is a distributed vector database developed by Zilliz and is one of the mainstream vector databases in the industry. It is primarily used for similarity search and large-scale vector retrieval, commonly found in AI scenarios such as image recognition, recommendation systems, natural language processing, and audio recognition. The name "Milvus" means "kite," which is a bird of prey.
Milvus can support storing tens of billions of vectors, which is made possible by its cloud-native architecture:
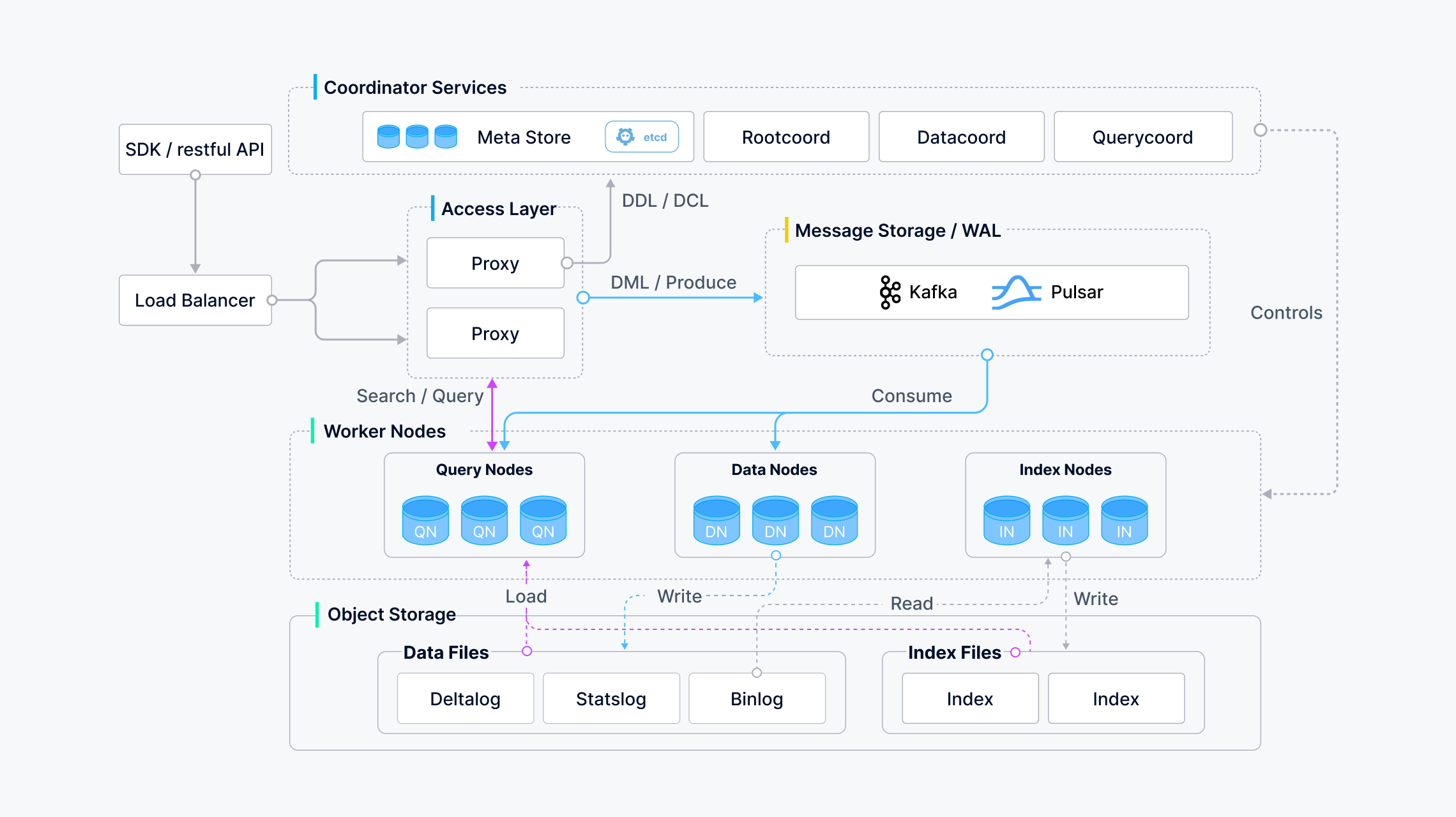
Note: This shows the 2.5.x architecture diagram.
As shown in the diagram above, Milvus separates storage and computing components, with its own components being completely stateless, thus enabling convenient horizontal scaling. Milvus's worker nodes follow the principle of low coupling and are divided into three types: query, data, and index, which handle vector search, data processing, and indexing tasks respectively. Tasks are distributed among nodes through coordinators, and client traffic is load-balanced through proxy nodes.
Milvus depends on three stateful external components:
laure-fc4d79455/meta/session/datanode-5
{"ServerID":5,"ServerName":"datanode","Address":"192.168.0.33:21124","TriggerKill":true,"Version":"2.5.13","IndexEngineVersion":{},"ScalarIndexEngineVersion":{},"LeaseID":2902455202693735596,"HostName":"laure-fc4d79455-datanode-0"}
This contains information such as the node's ID, hostname, and connection address.
Milvus provides excellent support for Kubernetes, and the official Milvus Operator is available for deploying and managing Milvus on Kubernetes. However, the Milvus Operator is still limited in managing external components like etcd and MinIO, only providing functionality to spin up corresponding Pods without supporting comprehensive Day-2 operations.
KubeBlocks is a database-neutral control plane running on Kubernetes. Through the abstraction of Addons, KubeBlocks provides a unified interface supporting any type of database, covering various aspects such as startup scripts, lifecycle hooks, and configuration management. The KubeBlocks Milvus Addon not only manages the Milvus lifecycle and operations but also provides better management of the external components that Milvus depends on. Through the APIs of KubeBlocks, users can achieve consistent Day-1 and Day-2 operations across engines.
Due to Milvus's stateless nature, the KubeBlocks Addon implementation is quite straightforward.
KubeBlocks already supports etcd, Kafka, and MinIO Addons, so we can reuse these Addons to leverage the services they provide. This exemplifies the meaning of "blocks" in KubeBlocks - we can build a complex database system by assembling building blocks.
The following describes the specific implementation of the Addon. All content is based on KubeBlocks 0.9 API and Milvus version 2.5. For explanations of the KubeBlocks API, please refer to the official documentation.
First, we define two topology structures through ClusterDefinition: standalone and cluster, corresponding to Milvus's standalone and distributed versions. The former is used for small-scale testing, while the latter is suitable for large-scale production environments.
In the standalone version, all Milvus components run in a single Pod, using the built-in RocksDB as the message queue, thus only depending on two external components: etcd and object storage. To simplify the deployment process, we run these two components as Components. By declaring etcd and MinIO Components in the ClusterDefinition and referencing the corresponding ComponentDefinitions, we can start etcd and MinIO simultaneously when the Milvus cluster starts.
Since Services created by KubeBlocks follow the naming convention {clusterName}-{componentName}, and all Components come with a headless service by default, we can construct addresses like {{ .KB_CLUSTER_NAME }}-etcd-headless.{{ .KB_NAMESPACE }}.svc.cluster.local:2379 in the Milvus configuration file to connect to the corresponding services.
In the distributed version, Milvus splits into different components such as proxy, query, data, index, and coordinators. However, essentially, these components use the same container image, and all components share the same configuration file, differing only in startup commands. This highly unified deployment process facilitates our management of different components.
In the cluster version, we no longer run etcd and object storage as Components, but reference them as external services in the Milvus cluster. The distributed version of Milvus supports Pulsar and Kafka as message queues. Since the Kafka Addon in KubeBlocks has higher maturity, we use Kafka as the message queue. Similarly, it is referenced as an external service in the Milvus cluster.
KubeBlocks provides ServiceRef to reference external services. We first declare the ServiceRef needed by the Component in the .spec.serviceRefDeclarations field of ComponentDefinition, for example:
- name: milvus-meta-storage
serviceRefDeclarationSpecs:
- serviceKind: etcd
serviceVersion: "^3.*"
optional: true
Then, in the .spec.componentSpecs[*].serviceRefs field of the Cluster CR, we can pass in the corresponding ServiceRef. ServiceRef supports two reference methods:
1. Reference a cluster managed by KubeBlocks and select the corresponding service:
- name: milvus-meta-storage # Corresponds to the name in serviceRefDeclarations
namespace: kubeblocks-cloud-ns # The namespace where the referenced Cluster is located
clusterServiceSelector:
cluster: rice6-849768d46
service:
component: etcd
service: headless # Corresponds to .spec.services in etcd ComponentDefinition
port: client # A port defined in .spec.services[*].spec.ports in etcd ComponentDefinition
Besides using regularly defined services, the service field in .clusterServiceSelector.service can also use a special service headless, which is the Headless Service created by default for each Component by InstanceSet. This service doesn't need to be defined in ComponentDefinition and can be used directly.
2. Reference an external address:
In the KubeBlocks API, there is a separate ServiceDescriptor CR to define this external address. For example:
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ServiceDescriptor
metadata:
name: etcd
namespace: kubeblocks-cloud-ns
spec:
host:
value: etcd-service
port:
value: "1234"
serviceKind: etcd
serviceVersion: 3.5.2
Then pass in the ServiceRef in the Cluster object:
- name: milvus-meta-storage
namespace: kubeblocks-cloud-ns # The namespace where the referenced ServiceDescriptor is located
serviceDescriptor: maple-7b759bdb4c-minio
The benefits of using ServiceRef include:
The Milvus Addon supports both ServiceRef reference methods. After configuring ServiceRef, we reference these ServiceRefs through the .spec.vars field in ComponentDefinition, for example:
- name: ETCD_HOST_SVC_REF
valueFrom:
serviceRefVarRef:
name: milvus-meta-storage
optional: true
host: Required
- name: ETCD_PORT_SVC_REF
valueFrom:
serviceRefVarRef:
name: milvus-meta-storage
optional: true
port: Required
These variables will be passed into the template when rendering configuration files. Since all Milvus components are stateless, there's no need to configure Volumes or lifecycleActions like roleProbe.
We can use the following Cluster CR to deploy a distributed version of a Milvus cluster:
apiVersion: apps.kubeblocks.io/v1alpha1
kind: Cluster
metadata:
namespace: kubeblocks-cloud-ns
name: maple-7b759bdb4c
labels:
helm.sh/chart: milvus-cluster-0.9.2
app.kubernetes.io/version: "2.5.13"
app.kubernetes.io/instance: milvus
spec:
clusterDefinitionRef: milvus
topology: cluster
terminationPolicy: Delete
componentSpecs:
- name: proxy
serviceVersion: 2.5.13
replicas: 1
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "0.5"
memory: "0.5Gi"
env:
- name: MINIO_BUCKET
value: kubeblocks-oss
- name: MINIO_ROOT_PATH
value: kubeblocks-cloud-ns/test-milvus
- name: MINIO_USE_PATH_STYLE
value: "false"
serviceRefs:
- name: milvus-meta-storage
namespace: kubeblocks-cloud-ns
clusterServiceSelector:
cluster: rice6-849768d46
service:
component: etcd
service: headless
port: client
- name: milvus-log-storage-kafka
namespace: kubeblocks-cloud-ns
clusterServiceSelector:
cluster: bambo-78dcc489cb
service:
component: kafka-combine
service: advertised-listener
port: broker
- name: milvus-object-storage
namespace: default
serviceDescriptor: maple-554bfbfc6b-minio
serviceAccountName: ""
disableExporter: true
# Configuration for mixcoord/index/query/data components is similar to proxy, omitted here
After creation, check the Pod status:

Due to the stateless nature of Milvus components, they support vertical scaling, horizontal scaling, and other operations without additional configuration. Additionally, native KubeBlocks operations such as cluster restart, stop, and minor version upgrades are also applicable to Milvus.
This article introduces the Milvus vector database and its deployment implementation on KubeBlocks. Milvus adopts a stateless distributed architecture, supports large-scale vector retrieval, and is commonly used in AI scenarios. KubeBlocks provides standalone and cluster deployment modes by reusing modular Addons such as etcd, Kafka, and MinIO, and achieves flexible expansion and simplified operations by referencing external services through ServiceRef.