Open-sourced by Yandex in 2016, ClickHouse is a high-performance, column-oriented OLAP database. Thanks to its columnar storage, vectorized execution, and high compression rates, it excels in scenarios like log analysis, ad serving, and financial risk control. ClickHouse's high performance is rooted in the partitioning and indexing designs of its MergeTree family of table engines, which allow for parallel query and background merge processing. Combined with a native distributed architecture for sharding and replication, it can maintain millisecond-level response times even with petabytes of data.
![]()
However, this extreme performance comes at the cost of high operational complexity. Many teams find that deploying ClickHouse in an enterprise-grade production environment is challenging. The main challenges are:
Simply packaging ClickHouse as container images and deploying them with StatefulSets is not enough to solve these inherent operational problems related to cluster management and data reliability — an operator-first approach is required.
To effectively use ClickHouse in a production environment, the key is to automate complex operational knowledge. This is where a Kubernetes Operator comes in. It standardizes and automates operations like cluster configuration, scaling, and failure recovery, significantly reducing the need for manual intervention.
Kubernetes Operators encode operational knowledge into software, providing declarative management of complex stateful applications. For ClickHouse, this means automating tasks like cluster setup, configuration management, scaling operations, version upgrades, and monitoring integration.
KubeBlocks is also a Kubernetes Operator, but it provides a unified API for different database engines. By defining CRDs like ClusterDefinition, ComponentDefinition, ShardingDefinition, and ComponentVersion, it abstracts database clusters, allowing users to build and manage them flexibly, like building blocks.
For ClickHouse, KubeBlocks provides an out-of-the-box solution, including:
With these capabilities, users don't need to write complex operational scripts or learn a specialized ClickHouse Operator. They can use KubeBlocks' unified API to achieve a production-grade ClickHouse cluster management experience on Kubernetes.
KubeBlocks adopts a horizontal abstraction design pattern. The core is a unified Cluster API, with pluggable database engine support enabled by ComponentDefinition and Addon mechanisms. KubeBlocks' InstanceSet extends StatefulSets with specialized enhancements for managing stateful workloads. It provides Pod role awareness, flexible definition of shard/replica topologies, and enables parallel rolling updates and self-healing, providing greater operational autonomy. This design allows operational teams to manage heterogeneous database environments with a single interface, significantly reducing learning curves and operational complexity.
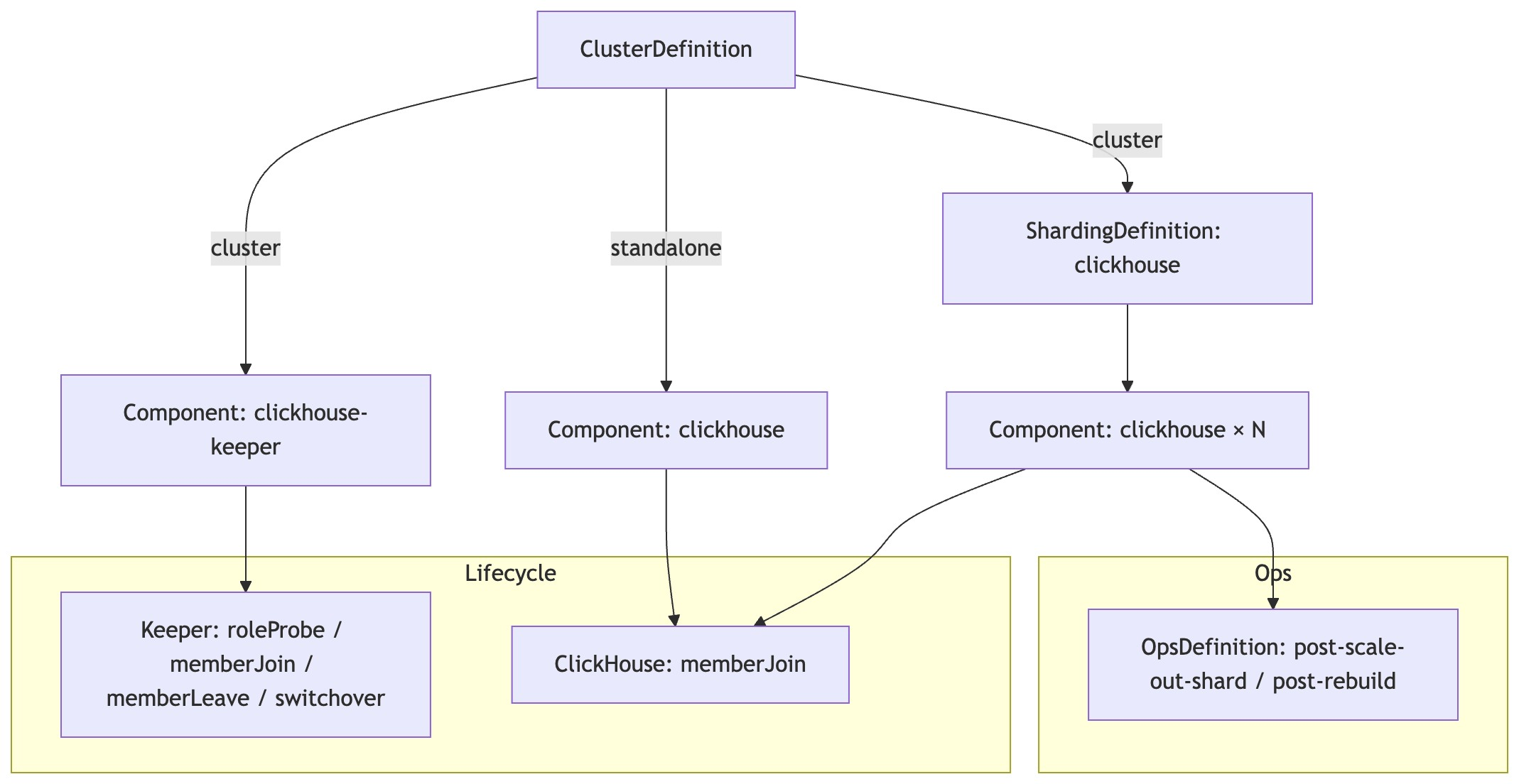
This section describes how KubeBlocks 1.0 API implements ClickHouse cluster management, high availability, parameter configuration, and backup/recovery. We've applied KubeBlocks' building block philosophy by splitting ClickHouse and ClickHouse Keeper into two components to create a basic, production-ready ClickHouse Addon.
ClickHouse cluster lifecycle management and operations mainly involve the following objects and responsibilities:
ClusterDefinition: Defines the topology and component orchestration.
ShardingDefinition: Associates with the clickhouse component, sets the minimum/maximum shard count, and configures concurrent creation/update policies for parallel operations during scaling and topology changes.
ComponentVersion: Declares supported versions and their image mappings.
ComponentDefinition (for clickhouse and clickhouse-keeper): Precisely defines the component's form and lifecycle management.
Underpinning all this is the InstanceSet, which is the core driver of the orchestration. Both the ClickHouse and Keeper components rely on it to ensure the orderly deployment and automatic recovery of shards and replicas, enabling lifecycle operations like scaling and rolling upgrades to proceed correctly based on roles and topology.
When these "LEGO blocks" are assembled, an autonomous ClickHouse cluster begins to take shape.
To discuss ClickHouse's topology, we must first talk about its table engines. ClickHouse's table engines can be grouped into three categories:
MergeTree Family: Stores data on local or external storage, using an LSM-Tree-like principle where background tasks continuously merge ordered data blocks. They support columnar storage, partitioning, sorting, and sparse primary key indices.
Special Purpose Engines:
Virtual Table Engines: Used to access external data sources like MySQL/PostgreSQL.
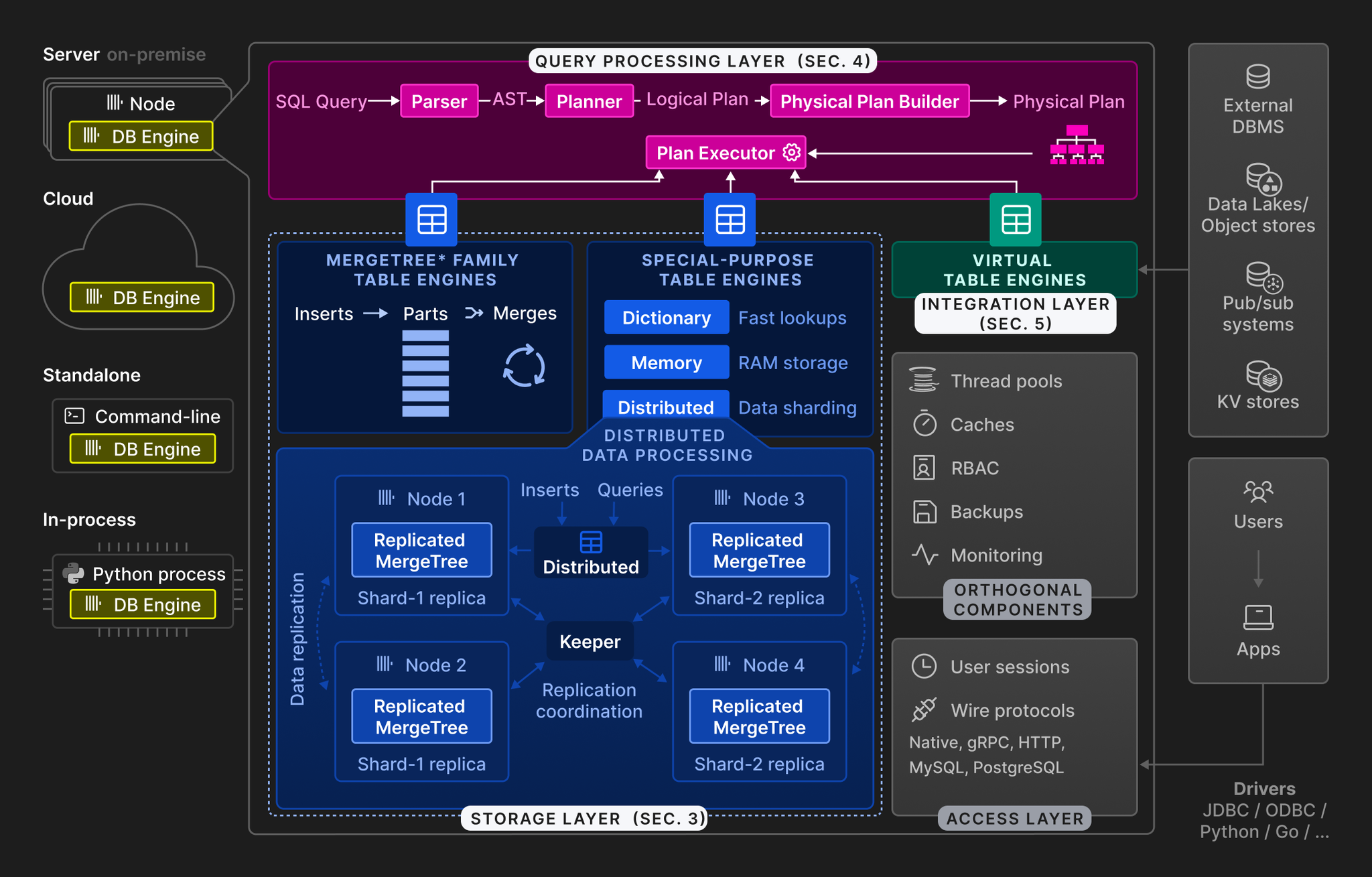
In practice, ReplicatedMergeTree and Distributed are a common engine combination, and their collaboration showcases ClickHouse's distributed architecture:
When executing DDL operations, the ON CLUSTER <clusterName> clause automatically distributes the statement to all nodes in the cluster. In the KubeBlocks implementation, the cluster name is dynamically injected via the INIT_CLUSTER_NAME environment variable, as shown in the Go template snippet below:
<remote_servers>
<{{ .INIT_CLUSTER_NAME }}>
{{- range $key, $value := . }}
{{- if and (hasPrefix "ALL_SHARDS_POD_FQDN_LIST" $key) (ne $value "") }}
<shard>
<internal_replication>true</internal_replication>
{{- range $_, $host := splitList "," $value }}
<replica>
<host>{{ $host }}</host>
{{- if eq (index $ "TLS_ENABLED") "true" }}
<port replace="replace" from_env="CLICKHOUSE_TCP_SECURE_PORT"/>
<secure>1</secure>
{{- else }}
<port replace="replace" from_env="CLICKHOUSE_TCP_PORT"/>
{{- end }}
<user from_env="CLICKHOUSE_ADMIN_USER"></user>
<password from_env="CLICKHOUSE_ADMIN_PASSWORD"></password>
</replica>
{{- end }}
</shard>
{{- end }}
{{- end }}
</{{ .INIT_CLUSTER_NAME }}>
</remote_servers>
ClickHouse's high-availability capabilities are primarily implemented through KubeBlocks' LifecycleActions interface. For example, a Switchover action can execute a custom script to switch the leader node when a ClickHouse Keeper leader needs to be taken offline, ensuring service continuity.
Additionally, KubeBlocks provides OpsDefinition to handle node failure scenarios. When a Pod is migrated to another node, the system automatically fetches and rebuilds the database and table schema from a live node, simplifying cluster recovery after a physical machine failure.
LifecycleActions are used to define the actions that the ClickHouse and ClickHouse Keeper components must perform at different lifecycle stages.
Since ClickHouse typically uses a Shared-Nothing architecture (users can also configure an S3 storage plugin for a Shared-Disk setup) and relies on Keeper for metadata management, the ClickHouse component itself requires relatively few LifecycleActions.
ClickHouse Keeper, as a Raft-based distributed coordination service, needs additional LifecycleActions related to the cluster's consensus state to ensure consistency is correctly maintained among Raft members during node changes.
ClickHouse Member Join: Horizontal scaling for ClickHouse can be either replica scaling or shard scaling. The core task is to replicate the table schema. For tables in the ReplicatedMergeTree family, the replication mechanism automatically backfills historical data.
Replica Scaling Process:
SHOW CREATE DATABASE ... FORMAT TabSeparatedRaw, and executes it on the new replica, verifying successful creation.Shard Scaling Process: Similar to replica scaling, but an instance from a different shard is selected as the synchronization source for database and table schemas.
Keeper Member Join: ClickHouse Keeper is a Raft-based distributed coordination service. Horizontal scaling requires adding the new Pod as a participant to the Raft cluster, following the NuRaft (C++ Raft library) specification, and having it enter a follower/observer state.
reconfig add "server.<id>=<fqdn>:<raft_port>;participant;1" is executed.get '/keeper/config' that the new FQDN appears in the configuration and the new member's role is follower or observer.Keeper Member Leave: A node is considered to have left when get '/keeper/config' no longer includes its FQDN.
reconfig remove <server_id> and verify the configuration no longer contains the FQDN.Keeper Role Probe: Uses the Keeper four-letter word (4LW) srvr to query the node's role: leader/follower/observer (a standalone node is treated as a leader).
Keeper Switchover: Switchover is a mechanism for a stateful service to actively switch leader, used to quickly elect a new leader when the current one is scheduled for shutdown, shortening the RTO (Recovery Time Objective).
reconfig add <base_config;priority>).KubeBlocks 1.0 API offers two configuration management methods: the ComponentDefinition's config controller and the parameter controller. The former is the default mode. If externalManaged: true and ParamConfigRenderer are set in the component definition, the parameter controller takes over configuration changes. The ClickHouse Addon uses the latter for more precise configuration management.
The following code block shows the configuration definition in the clickhouse ComponentDefinition. externalManaged: true indicates that the parameter controller is used for configuration management.
configs:
- name: clickhouse-tpl
template: {{ include "clickhouse.configurationTplName" . }}
volumeName: config
namespace: {{ .Release.Namespace }}
externalManaged: true
- name: clickhouse-user-tpl
template: {{ include "clickhouse.userTplName" . }}
volumeName: user-config
namespace: {{ .Release.Namespace }}
externalManaged: true
- name: clickhouse-client-tpl
template: {{ include "clickhouse.clientTplName" . }}
volumeName: client-config
namespace: {{ .Release.Namespace }}
restartOnFileChange: false
ParamConfigRenderer defines configuration file types, specifies events that trigger re-rendering, and binds a set of ParametersDefinitions for fine-grained control over parameter rendering and value constraints.
apiVersion: parameters.kubeblocks.io/v1alpha1
kind: ParamConfigRenderer
spec:
componentDef: clickhouse-1.0.1-beta.0
configs:
- fileFormatConfig:
format: xml
name: user.xml
templateName: clickhouse-user-tpl
- fileFormatConfig:
format: xml
name: 00_default_overrides.xml
reRenderResourceTypes:
- hscale
- shardingHScale
templateName: clickhouse-tpl
parametersDefs:
- clickhouse-user-pd
- clickhouse-config-pd
The ClickHouse Addon integrates the open-source Altinity clickhouse-backup tool to provide full and incremental backup/recovery capabilities. For a clustered ClickHouse deployment, the KubeBlocks Operator selects the first Pod in each shard to perform the backup/recovery operation.
{layer}/{shard}/{replica}) and macros configuration, DDL is not distributed with ON CLUSTER. Instead, the table schema is recovered for each shard separately.The RBAC synchronization mechanism relies on the user_directories.replicated.zookeeper_path configuration. It uses Keeper as the distributed storage for user permission data, ensuring permissions are automatically synced across the cluster.
<clickhouse>
<user_directories>
<replicated>
<!-- Keeper-based replicated user directory -->
<zookeeper_path>/clickhouse/access</zookeeper_path>
</replicated>
</user_directories>
</clickhouse>
Steps for installing KubeBlocks 1.0 are omitted here for brevity.
# Add the Helm repository
helm repo add kubeblocks https://apecloud.github.io/helm-charts
helm repo update
# Install the ClickHouse addon
helm install clickhouse kubeblocks/clickhouse --version 1.0.1
# Create a ClickHouse cluster (3 shards x 2 replicas + 3-replica Keeper)
helm install ch-cluster kubeblocks/clickhouse-cluster \
--version 1.0.1-beta.0 \
--set shards=3 \
--set replicas=2 \
--set keeper.replicas=3
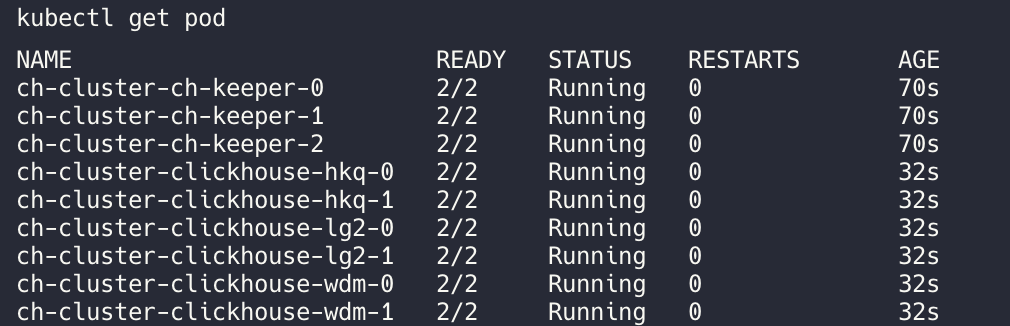
You can find various example scenarios in the repository: kubeblocks-addons/clickhouse.
This article demonstrates KubeBlocks' comprehensive solution for the cloud-native adoption of ClickHouse.
In today's increasingly competitive OLAP landscape, emerging engines like DuckDB have outperformed ClickHouse in specific scenarios. However, in enterprise-grade distributed data processing, ClickHouse remains irreplaceable due to its mature distributed architecture, diverse table engines, and powerful query optimization. Cloud-native transformation is crucial for reducing ClickHouse's operational complexity and improving ease of use.
As an open-source Kubernetes Operator for stateful services, KubeBlocks abstracts complex database operational tasks through a standardized, declarative API. Its unified cluster management model, flexible component orchestration, and deep support for core ClickHouse scenarios-including Keeper high availability, shard management, parameter configuration, and backup/recovery-provide enterprises with a production-grade cloud-native solution for ClickHouse.
In the future, we hope to validate and optimize KubeBlocks for ClickHouse in more production scenarios. We welcome you to join our community, exchange ideas, and contribute to the project!